
MySQL 亿级数据量查询优化方案
背景
最近业务上有一个需求,涉及到两张表的联查,条件也只有三个。是不是听起来很简单?但这两张表一张是 2.5 亿,一张是 4.5 亿。加起来将近 7 亿的数据。之前我自己了解的是 MySQL 单表数据建议存储量也就是 2000w,所以听到这两张表的大小时也很震惊。但凡事都得有个解决方案,在使用了索引等工具,把这次的过程分享一下。
优化方向
首先我们得先有一个方向,按照性价比从高到低分别是 索引的建立和优化 ->SQL 语句的优化 -> 表结构的优化 -> 硬件层次的优化。索引是最简单而且效率最高的一种手段,我们一般在优化 SQL 的时候都会用到,再下来是 SQL 语句本身,只展示出需要的字段,以及 SQL 语句本身是否走了索引,索引是否失效等等,关于 SQL 优化理论可以看我这篇文章
再往下是表结构的优化,首先是数据类型的选择,例如年龄,很多人用的是 int 类型存储,但完全可以使用 tinyint 来代替,将其从 4 字节变为 1 字节,同理还有 char 和 varchar,varchar 是可变字符,用多少占多少,而 char 是固定占用设置的空间,对于 text 的话,尽可能不去使用,再深度一点的就是对于数据存储的方式,水平分库分表等等…… 最后是硬件层次的优化,这个是成本最高的,往服务器中多加一点 CPU,多分配一点资源。以上就是我们优化 SQL 的几种方向,这次我们仅使用前两种方式来优化这 7 亿的数据
索引
我们都知道索引的强大,将无序的数据变为有序,首先我们需要给外键加一个索引,也就是这两张表的连接条件的那两个字段,如果有等值匹配的条件字段也可以加,但如果是模糊查询的话就要注意了,因为左 LIKE 和全模糊会导致索引失效,如果想要模糊查询,可以考虑用搜索引擎实现。时间字段也是可以加索引的以及 order by 的字段,加完索引后我们可以使用 explain 执行计划来看一下是否用到了索引
SQL 语句调优
对于 SQL 语句来说,我们只返回我们想要的字段就可以,尽量避免返回无用字段,例如使用 SELECT *,另外也不要在 SQL 语句中进行函数运算,这也会导致索引失效。不要连接过多的表,阿里巴巴的编程规范约定的表是不能超过 3 张以上。在连接的时候也使用小表去连接大表,这样可以减少表连接的创建次数,避免浪费数据库资源,加快查询速度。
SQL 优化实战
因为公司的一些保密协议,所以我自己建立一个小 demo 来测试,数据是 3000w,虽然数据有点少,但主要提供一个思路,大家当个参考就可以。数据实在是加不动啦,从早上 9 点一直执行到下午 5 点才加了 3000w
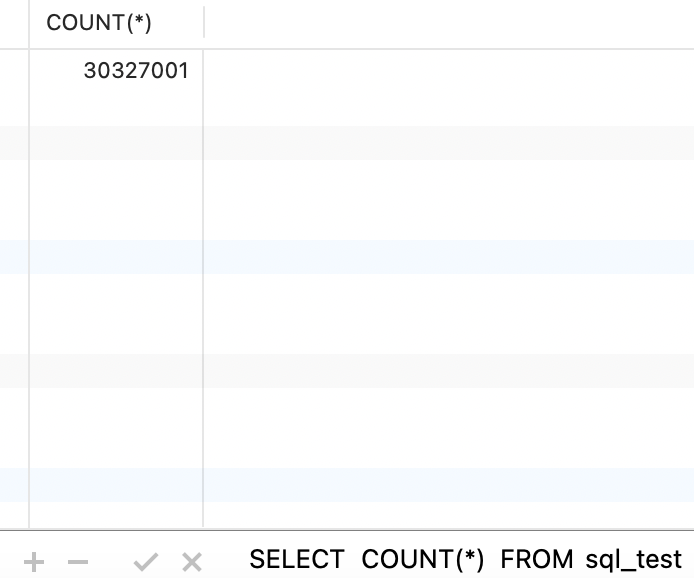
先按照 name 等值查询表,这条 SQL 的执行时间是 23s,算是非常长的了

使用执行计划看一下,自然走的是全表扫描
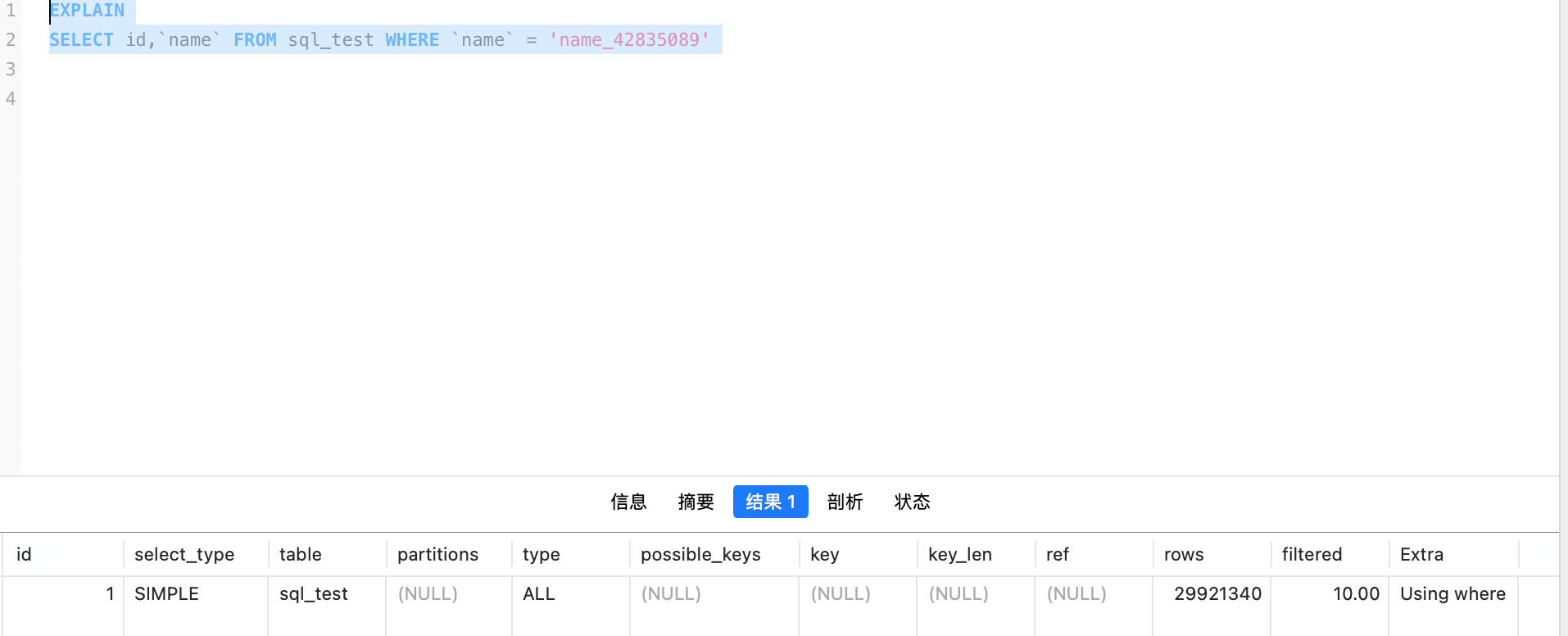
现在我们尝试加一个索引,格式如下:CREATE INDEX 索引名称 ON 表名 (字段),这里默认加的是普通索引

现在我们再查询一次,可以看到速度直接降到了 0.002s,算下来直接快了 1 万多倍。当然数据越多索引带来的效率提升也是非常明显的
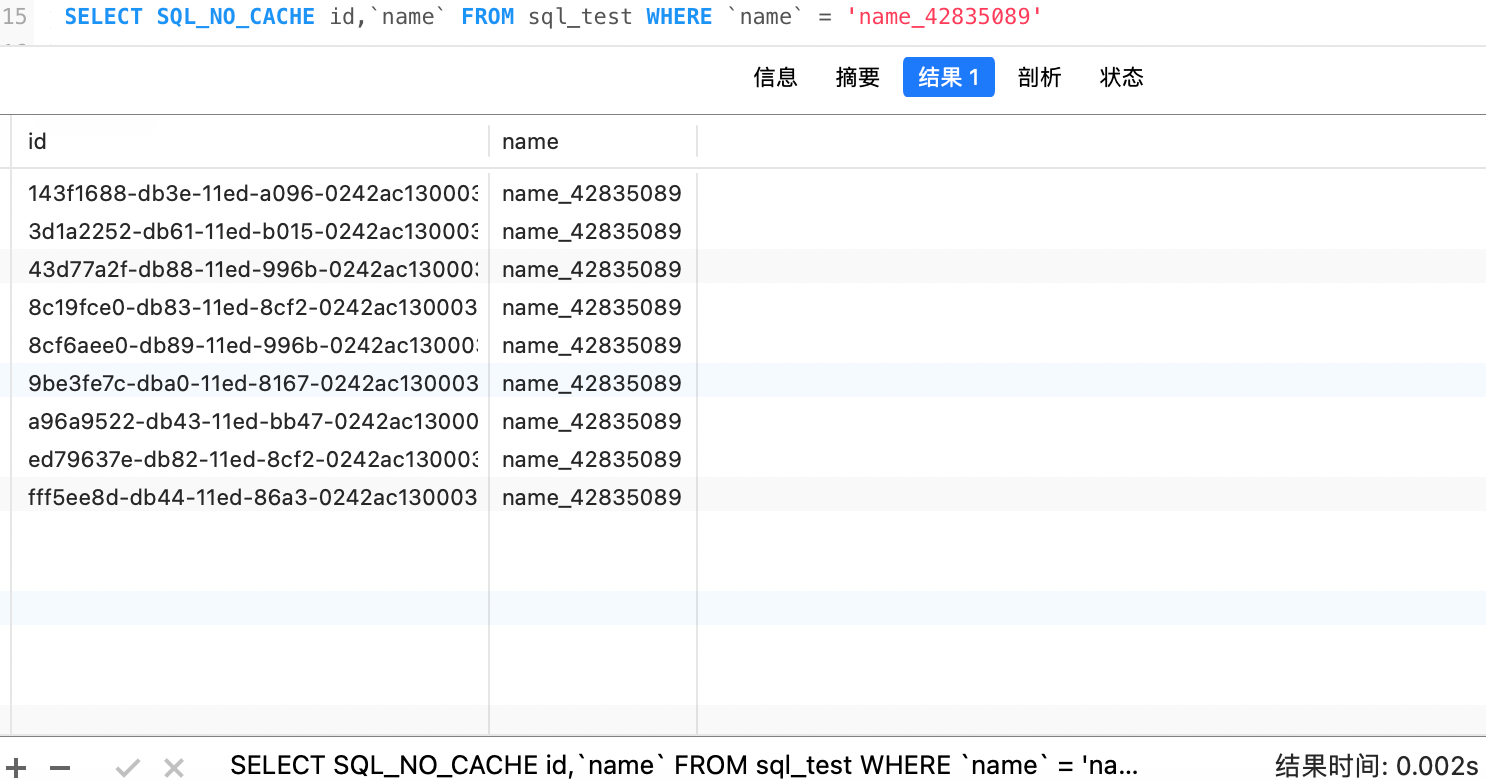
看一下执行计划,索引类型是 ref,使用到了普通索引,并且 filtered 是 100%,这个值是查找行数占结果的百分比,越高越好,rows 为 9,表示只查询了 9 行就返回了全部数据

小 demo 的测试就算测试完成了。可能有人会说这个数据和 7 亿差的太多了,但 7 亿那个我也用的是同样的方法,加了索引,在 SQL 上避免索引失效,执行结果也在 1s 以内。这点不用担心,只要我们掌握了方法,自然可以完成对 SQL 的优化
 微信
微信- 支付宝









