
在 java 中使用 deepseek 并接入联网搜索和知识库
前言
当前 AI 技术生态以 Python 为主导,这几天在研究用 Java 搭建知识库使用,最终都避不开 Python,于是打算记录下结果,目前是有 2 个方案,第一个方案是 在 Python 中使用 embedding 嵌入模型,完成数据向量化与向量搜索,推荐使用这个方案,简单也方便。第二个方案是不使用 embedding 嵌入模型,使用 es 来完成向量存储,但仍需要 Python 来完成数据的向量化。
本文分为三部分,第一部分是接入 deepseek-r1,第二部分是接入联网搜索,第三部分是使用自建知识库(两个实现方案),知识库为可选功能,并且实现起来也挺麻烦,不需要的可以直接看前两部分即可。
同时,本次的代码也已经放在了 GitHub 上,deepseek-java
前置准备
首先介绍一下本次的开发环境:
Java17 + SpringBoot 3.3.2
Python 3.11
deepseek 的 APIkeys(在官网上买就可以了)
tavily(搜索引擎,通过这个实现联网搜索,在第二部分会具体说)
项目依赖
我们需要一个 SpringBoot 的项目,具体依赖如下
1 | <dependencies> |
第一部分 - 接入 deepseek-r1
获取 ApiKeys
操作步骤如下,进入 deepseek 官网,充值余额,生成 key 即可。
编写基本代码
封裝聊天请求类,包含四个基本参数。
1 | public class ChatRequest { |
这里是核心功能类、实现了基本对话功能的代码,只需要配置 API_KEY 变量就可以启动测试,默认使用 deepseek-r1,你也可以改为 v3。
1 |
|
第二部分 - 接入 联网搜索
联网搜索我们需要借助一个免费的 ai 搜索引擎实现,每个月有 1000 次搜索次数,已经足够日常使用了。官网: Tavily 注册完成后创建一个 ApiKey 即可。
添加一个搜索类,负责实现我们的搜索逻辑,同样只需要替换 apiKey 的变量即可。
1 |
|
然后在核心类中引入搜索类,并在向 ai 提问前先去搜索并提前加入到 prompt 中,此时核心类如下:
1 |
|
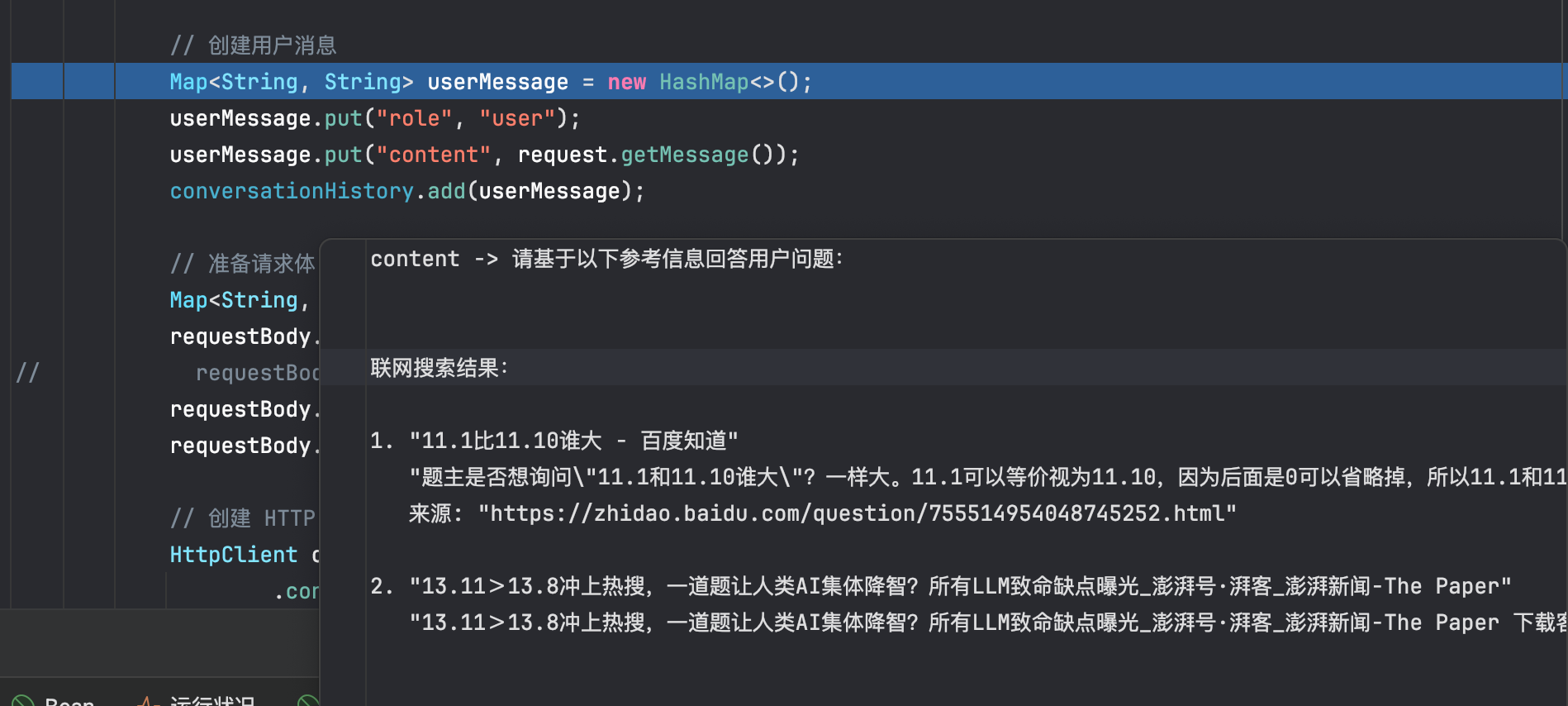
此时可以看到,在创建用户消息前,请求参数中就已经存在联网搜索的结果。
第三部分 - 接入 自建知识库
知识库部分的实现有 2 种方式,推荐采用 embedding 方案(效果更优且维护成本低),ES 方案适用于已有 ES 技术栈的场景
通过 embedding 嵌入模型 实现
首先我们要先搞明白,什么是 embedding 嵌入模型?embedding 是机器学习的核心技术之一,通过将离散(文字、图片等)的数据转为连续的向量空间,并捕获数据特征。例如我们搜索的时候, 输入可爱的猫图,那么 embedding 就会把这五个字转为数字数组得到向量,再根据这个向量和所有的数据向量距离进行对比,数值越近说明越相关。最后按照相似度把数据返回给我们。
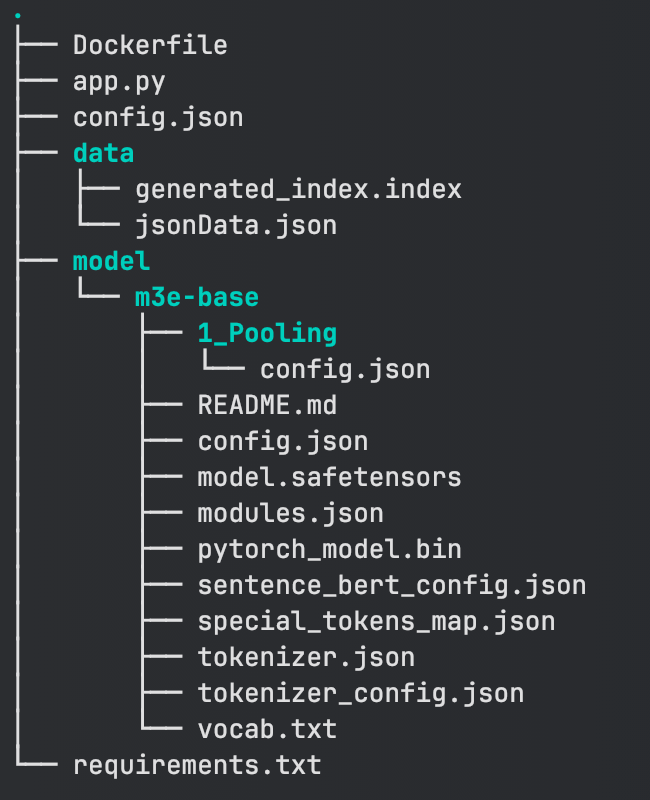
数据向量化我们需要借助 python 实现,python 项目结构如下,忽略 Dockerfile。app.py 是代码的主体,config.json 是配置文件,我们只需要改动这个地方即可。data 下存放的是我们知识库元文件及索引文件(刚开始没有 index 文件属于正常的,因为 index 是基于 json 格式的知识库生成的)。model 则是我下载的 embedding 模型,最后 requirements 则是依赖表。
下面介绍具体的使用方式:
创建项目,下载 m3e-base 向量模型
1 | git clone https://huggingface.co/moka-ai/m3e-base ./model/m3e-base |
执行完成后注意,需额外手动下载两个配置文件。进入 huggingface 的地址:m3e-base,手动将这两个文件下载下来,放到 model 目录内。
创建 app.py 文件,不需要改任何地方
1 | import os |
创建 config.json 文件,下面是每个参数具体的意思:
model_path:向量的预训练模型的路径
index_file:搜索时使用的向量索引的文件路径
json_data_file:搜索时使用的原始数据的 JSON 文件路径
faiss_dir:根据原始数据 JSON 生成的 faiss 文件存储路径
vector_dim:向量的维度大小
default_top_k:默认情况下返回的最相似结果的数量
similarity_threshold:相似度阈值(仅返回高于该值的结果)
server_port:服务端口号
debug:调试模式
result_format:
- include_score:返回的结果中是否包含相似度得分
- max_content_length:返回结果中内容的最大长度,超出部分会被截断
data_fields:
- metadata_fields:原始数据中,除向量字段外的所有字段
- content_field:原始数据中的向量字段(只能有一个)
下面我简单说一下要如何配置,model_path 是我们的向量模型路径,这里我用的是 m3e-base 模型,模型小而且效果不错,后面会使用该模型做演示并下载到本地,index_file 和 json_data_file 是我们在做向量查询时使用的文件。其中 index 作为索引,json 作为元数据使用。faiss_dir 则是我们调用 generate-index 接口后生成的索引文件路径。vector_dim 向量维度是跟向量模型本身挂钩的,例如 m3e-base 这个模型的维度就是 768,不可以设置别的值。下面几个参数上面也说的很清楚了。最后一个参数是重点,这个是负责匹配我们知识库元文件字段的,目前大部分源文件格式都是 json,但是字段不可能都一样,所以这里需要配置各自的字段,例如我的元文件字段有四个,需要按照 content 字段做搜索,那么这个字段就是向量字段。
1 | { |
最后则是 requirements 文件,创建后,直接 pip install -r requirements.txt 安装依赖即可。
1 | blinker==1.9.0 |
现在我们可以开始启动了,刚刚我们已经安装了 m3e 向量模型,并下载了依赖。先简单介绍下逻辑和使用方法:
项目在启动时会加载当前目录下的 config.json 配置文件,随后读取 data 目录下的索引和元数据,启动成功后对外暴露 2 个接口,分别是 /api/search 向量查询接口 和 /api/generate-index 生成 index 索引接口。前者为 get 请求,参数为 query,返回跟 query 相近的数据。后者参数为文件,入参名为 file,传入元数据后,生成对应的 index 索引。
使用方法: 配置 config.json,项目启动后,调用 /api/generate-index 接口,参数是你的知识库 json 元文件,然后把生成的 index 索引以及你的 json 原文件放到 data 目录下,修改 config.json 中的 index_file 和 json_data_file,将这两个变量指向 data 目录下的索引和元文件(在文章的最后提供了测试用的元数据)
到这里,python 的部分就完成了,下面只需要在 Java 核心类中调用 Python 的 /api/search 向量化查询用户的问题,就可以启用知识库了
1 | // 获取搜索结果(如果已经添加了联网搜索,不要加入这一行代码) |
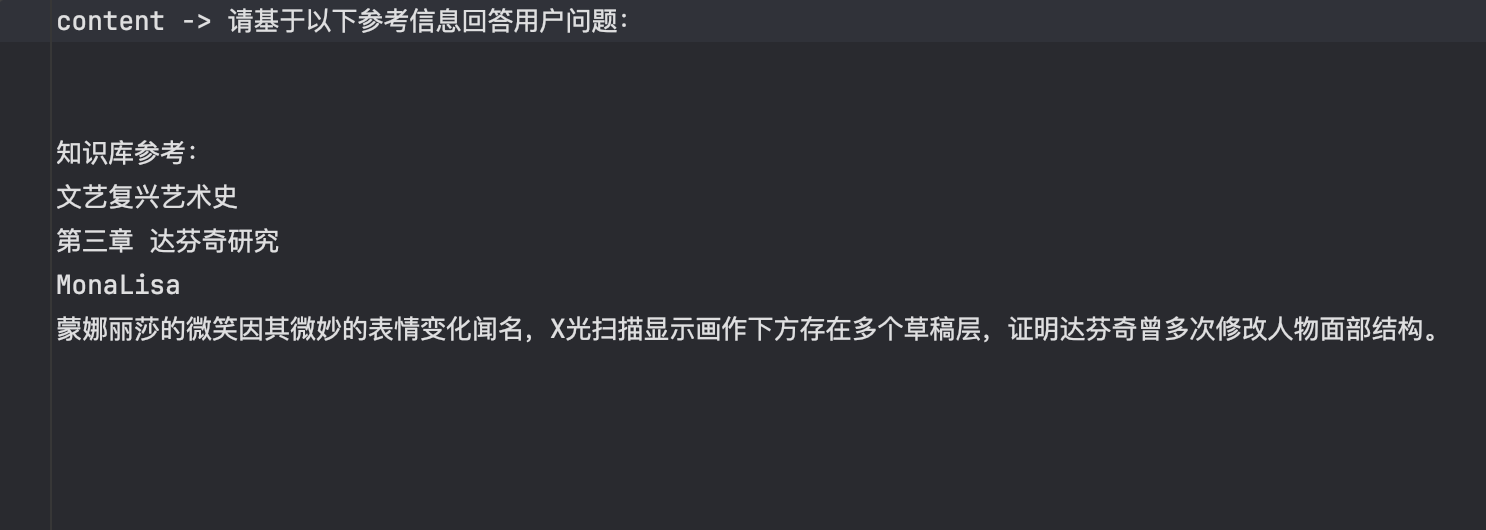
知识库查询测试,入参为 蒙娜丽莎是谁? 成功匹配知识库内容
通过 elasticsearch 向量搜索实现
首先我们需要安装好 Elasticsearch 8.17.2 + Kibana 8.17.2
Java 中引入 es 依赖:
1 | <!--知识库依赖(注意 es 的版本与自己的对应)--> |
继续新增 es 搜索类
1 |
|
搜索类加入知识库逻辑(注意位置):
1 | // 是否启用知识库 |
python 代码如下,完成对 json 原数据存入 es 以及查询向量化
1 | import json |
python 依赖:
1 | aiohappyeyeballs==2.5.0 |
使用方法:
- 修改 es 搜索类和 Python 脚本中的 es 地址
- 调用 Python 的 save_to_es 接口,参数名为 file,类型是 json 文件。将测试文件加入到 es 的索引中(测试数据放下面)
- 调用 Python 的 msg_to_vector 接口,参数为 msg,查看是否正常
- 正常使用,知识库接入完成
测试元数据
1 | [ |
 微信
微信- 支付宝







