
在项目中引入 ShardingJDBC 并整合 MybatisPlus
ShardingJDBC 介绍
SharingdJDBC 是 ShardSphere 中的一种实现方式(ShardingSphere-Proxy 是代理,相当于一个中间件,把所有的请求统一发到 Proxy 上,在 Proxy 上对请求进行处理;最后一个是 Sidecar,相当于提供一个大网,将所有的数据库织起来,一般用于微服务中)它一个轻量级的 Java 框架,集成在程序里,通过 jar 包的方式提供服务,并且支持很多 ORM 框架,比如我们经常使用的 Mybatis、JPA、Hibernate 等等
ShardingJDBC 的一些概念
逻辑表:我们一般把结构和逻辑一致的表称为逻辑表,例如 user 表我拆分为了 user01 和 user02,除了名字以外,其他都一样,那么 user 就是一张逻辑表。
真实表:真实表就是真实存在的表,上面的 user01 和 user02 就是真实表
广播表:公用的一些表,相当于抽象版的” 工具类”
分片键:我们分表是按照哪个字段去分,这个字段就是分片键
分片算法:确定分片键后要如何去计算到具体的表。常用的有取模运算、hash 算法以及范围算法 `
分片策略:由分片键和分片算法组成。用于确定数据应该存储在哪个分片中的算法或规则。例如行表达式分片策略、标准分片策略、范围分片策略…
分片规则管理器:负责管理分片规则和分片策略,根据分片规则将数据分配到不同的数据库节点中。
数据库路由器:根据 SQL 语句中的分片键,通过分片规则管理器将数据路由到相应的数据库节点中。
数据库代理:负责将 SQL 语句发送到相应的数据库节点,并将结果合并后返回给客户端。
项目实战
引入依赖
我们在项目中引入一个 Sharding 的依赖,这里我用的是 5.2.1 版本。本次我也整合了 MybatisPlus,所以需要多引入一个 MybatisPlus 的依赖以及 druid 连接池
1 | <!--ShardingJDBC--> |
配置文件
ShardingJDBC 最核心的就是配置部分,这里我使用单库双表实现水平分表先做个小 demo,帮助大家快速了解认识 Sharding。
我在数据库中有 2 张表,分别为 sora_user01 和 sora_user02。打算每次插入数据的时候根据 id 取模判断应该落到 01 还是 02。然后用户读取的时候从 2 张表中一起获取数据。
水平分表可以降低单表的数据量。demo 后面会用 2 个数据源和 2 张表来还原项目的真实情况
1 | server: |
Sharding 的配置我把它分为三大类,分别是逻辑表的配置分表 / 分库策略 id生成策略
这三个都要配置在 rules 下的 sharding 中
首先来说说分表 / 分库的策略配置,这部分对应的是配置文件中的 sharding-algorithms,我们需要先配置算法名称,这个是自定义的,例如我们给 user 表配置分片算法,那么就可以叫 user-inline。随后在算法中配置 2 个属性,分别是 type 类型,我们使用 INLINE 表达式。然后是 props 中的 algorithm-expression 配置分片算法的具体逻辑。我这里按照 id%2+1,平摊在 01 和 02 两个表中。
再来说逻辑表的配置,对应配置文件中 tables,我们首先配置表名,这个是自定义的名字,我习惯跟 Java 的实体类对应(我也试过使用过数据库的表名字发现有问题)。接着需要配置真实表,也就是 actualDataNodes 的内容,由数据源 + 表名组成,配置文件中的注释写的很清楚。下面是分片策略 tableStrategy,这个是固定的。我们需要选择一个分片策略。ShardingJDBC 一共有 4 种分片策略。
standard-适用于单分片键场景
complex-适用于多分片键场景
hint-通过Hint指定分片值进行分片
none-不分片
我们一般使用单分片键来进行分片,所以选择 standard。配置 2 个属性,分别为分片列,也就是按照哪个字段进行分片。第二个属性为分片算法,我们引入刚刚自定义的 user-inline 算法就可以。
最后是主键的生成策略,一般分布式项目我们使用雪花 id 就可以了,固定使用 SNOWFLAKE 来完成。
如果没有看明白或者想了解更多的可以去看看官网的说明
后端代码
经典的 MybatisPlus,这里就不过多赘述了
新增用户的代码:
1 | /** |
查询代码:
1 | /** |
测试结果
以上的工作完成后,就可以试验了,先使用 postman 添加了 11 条数据
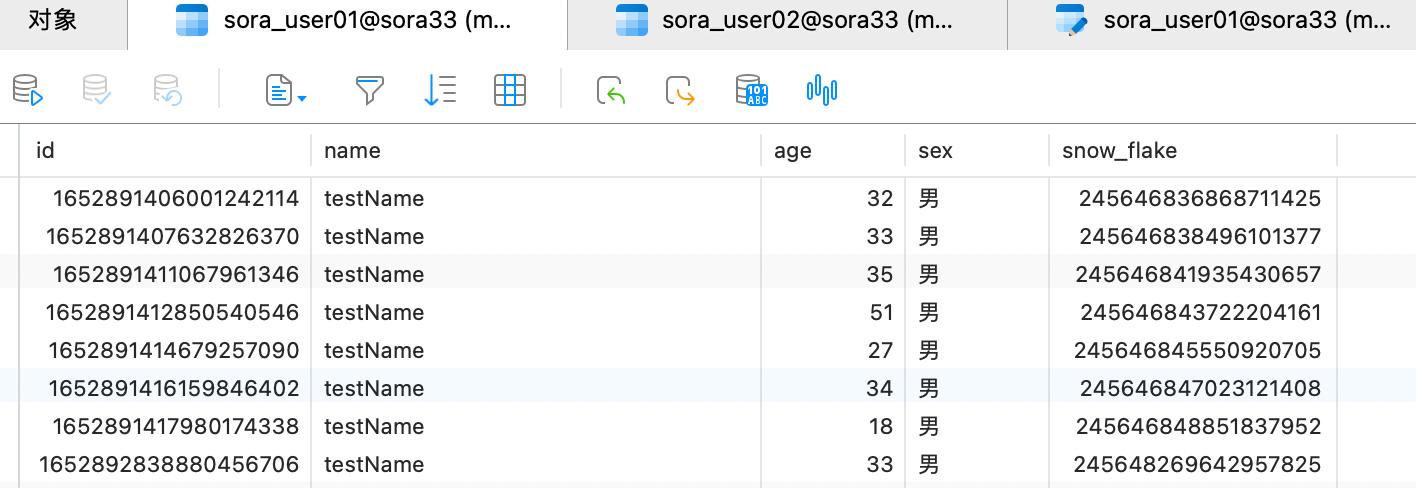
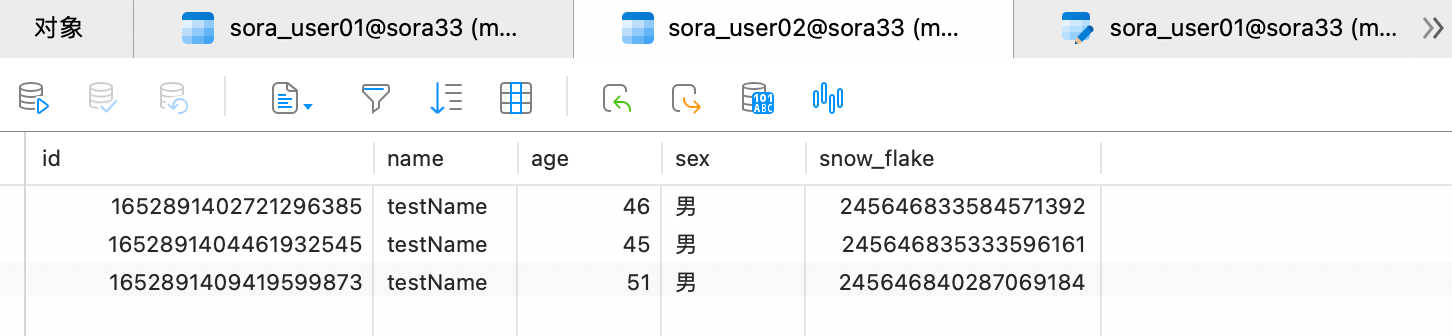
可以发现 id 尾数为奇数的在 02 表中,id 为偶数的在 01 表内。成功按照分片策略添加成功。接着我们试一下查询

发现报错了,说的是和分片算法不匹配。
我们看一下源码,发现 id 是 String 类型的,String 类型是不可以直接使用 % 运算的。
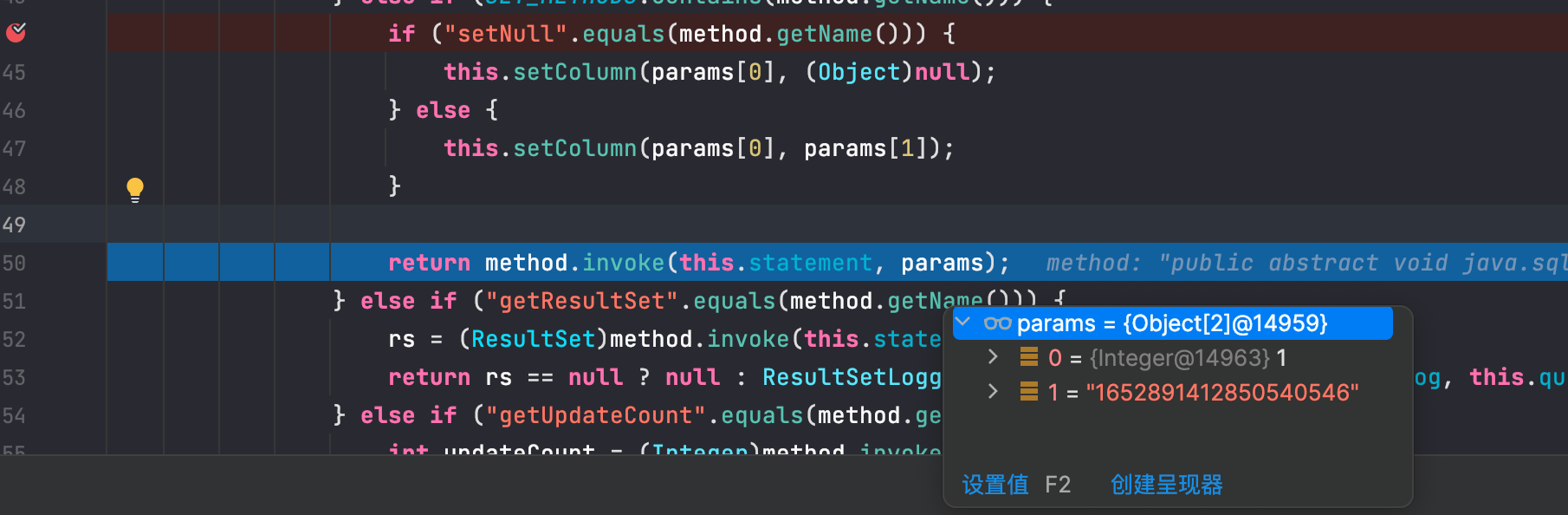
看一下 controller,将 String 改为 Long 即可
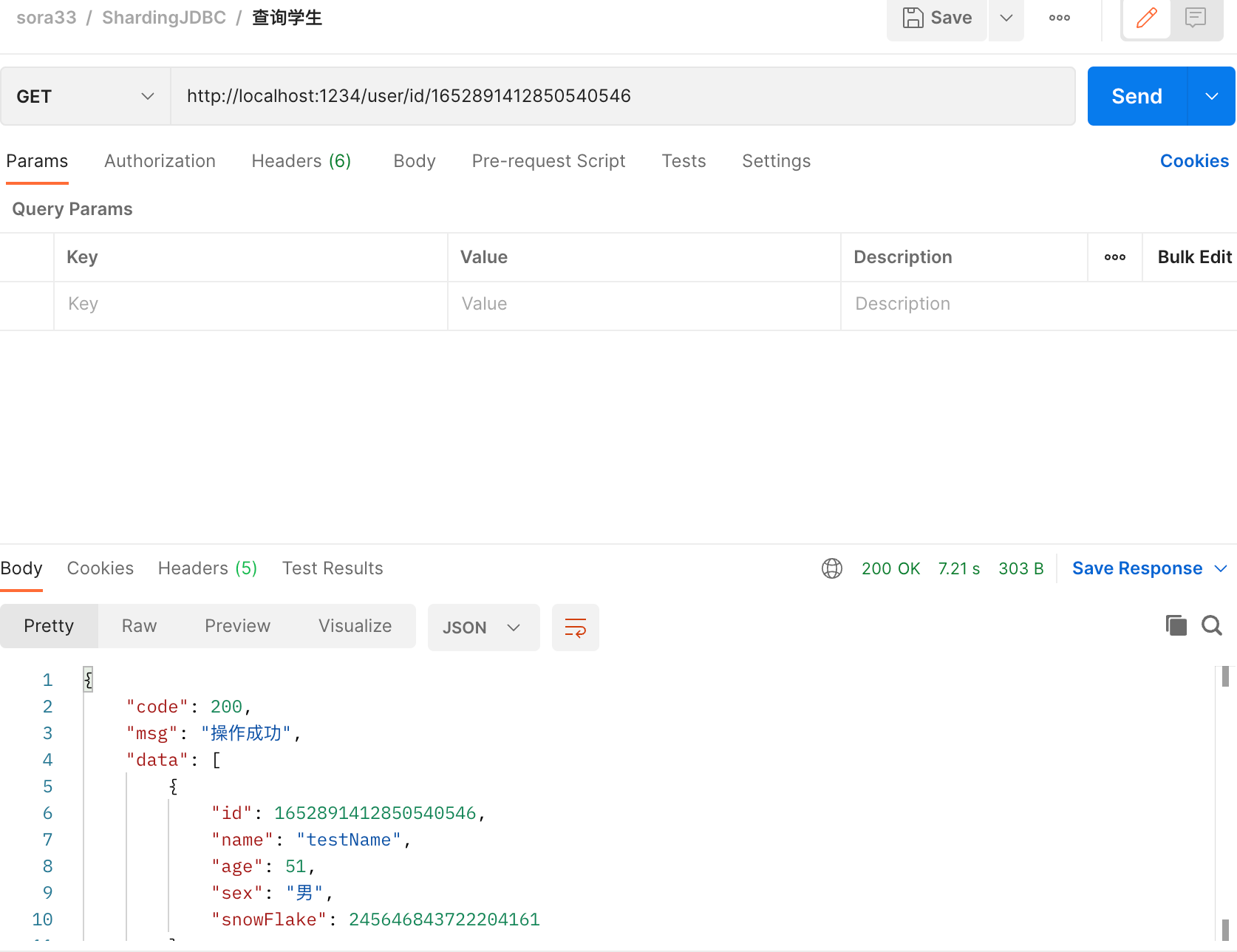
再试一次,查询成功
当然排查这个错误,我自己也排查了将近半天,各种论坛和 github 也提问了,期间也问了很多次 ChatGPT 也没结果,最后反正就是看到 GPT 在 INLINE 表达式中用了 Math 函数才突然有了灵感🤔
双数据源双表实战
我们接下来尝试在 2 个数据源中分库分表的策略。还是一样我们加一个分库的策略,叫 database-inline,然后在 tables 表中引入 database 的分片策略。
1 | #shardingjdbc主要配置 |
根据上面的配置我们可以推断出来。id 的尾数只有可能是偶数或奇数,偶数的话,分库算法模出来的就是 0 也就是 ds0 数据源,同理,分表算法模出来的是 0+1 也就是 user01 表,那么反之,奇数对应的是 ds1 数据源的 user02 表。我们还是先插入几条配置。
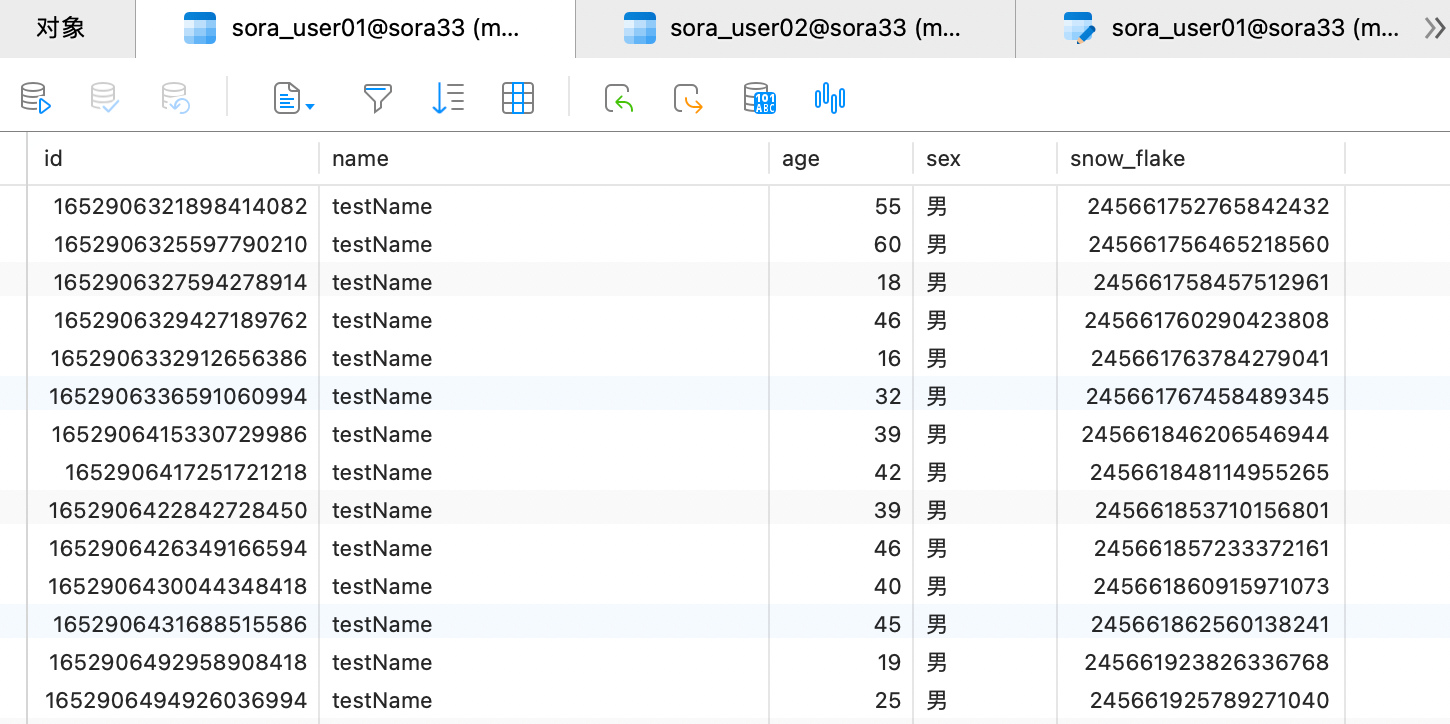
ds0 的 user01 表的数据:
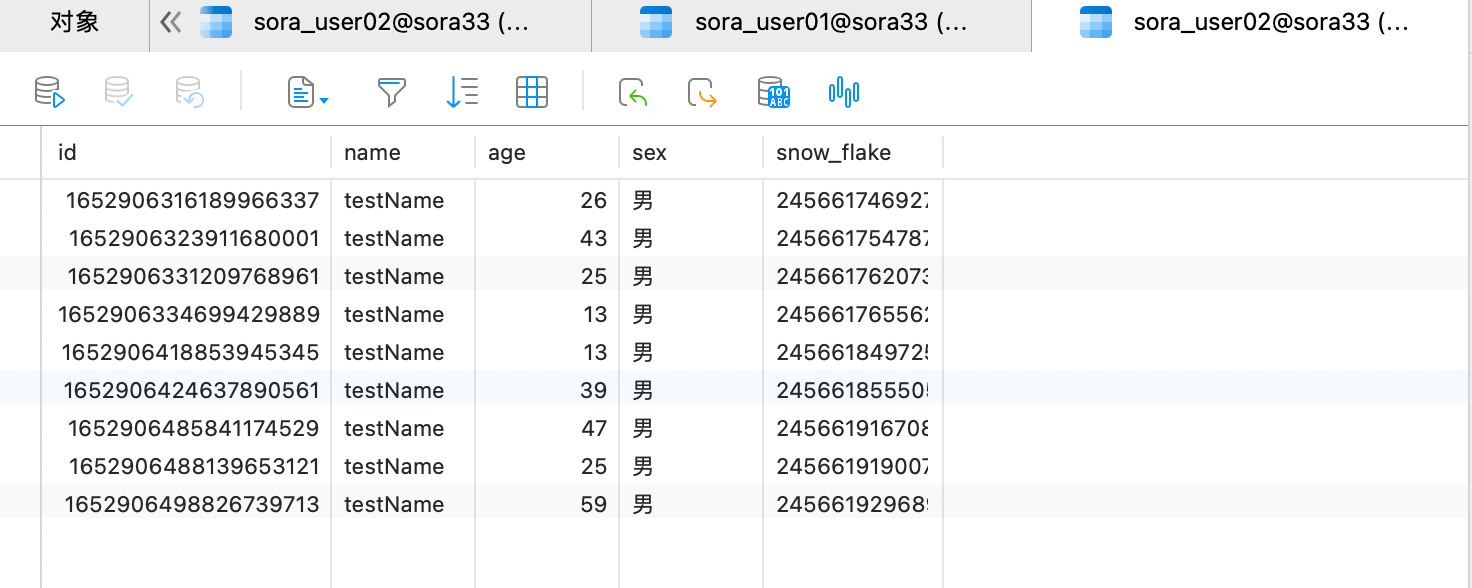
ds1 的 user02 表的数据:
然后我们分别用 01 的 id 和 02 的 id 去查询都是可以查出来的,这里我就不放图了
实现原理
功能上实现后我们就可以分析一下实现流程了。
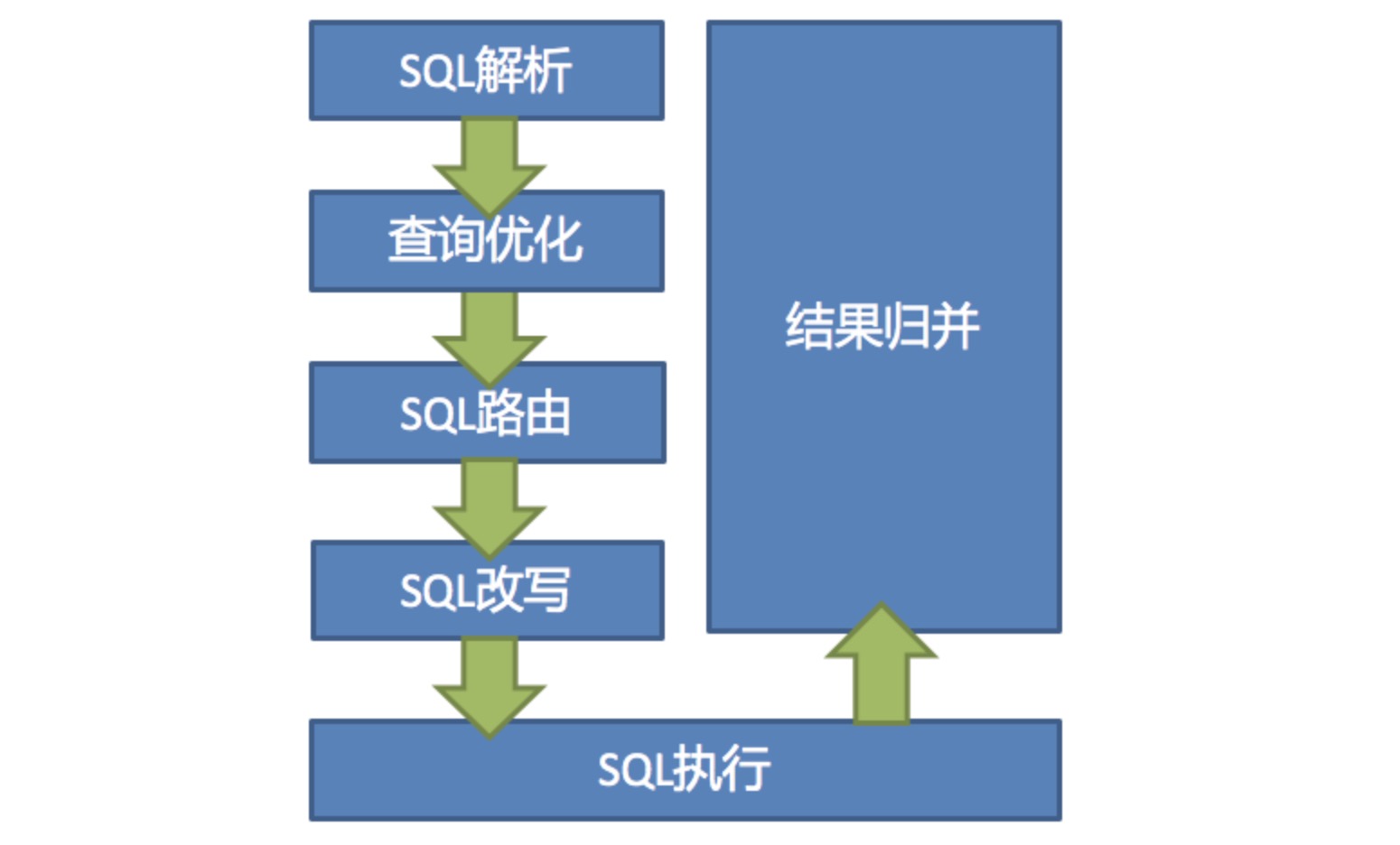
这里我先把官方的解释放出来
SQL 解析
分为词法解析和语法解析。 先通过词法解析器将 SQL 拆分为一个个不可再分的单词。再使用语法解析器对 SQL 进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
SQL 路由
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
SQL 改写
将 SQL 改写为在真实数据库中可以正确执行的语句。SQL 改写分为正确性改写和优化改写。
SQL 执行
通过多线程执行器异步执行。
结果归并
将多个执行结果集归并以便于通过统一的 JDBC 接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
查询优化
由 Federation 执行引擎(开发中)提供支持,对关联查询、子查询等复杂查询进行优化,同时支持跨多个数据库实例的分布式查询,内部使用关系代数优化查询计划,通过最优计划查询出结果。
经过我自己的整理我把它分为了 4 步
- 客户端发送 SQL 语句到 ShardingJDBC。
- 数据库路由器解析 SQL 语句,提取分片键。
- 数据库路由器通过分片规则管理器获取数据应该存储在哪个数据库节点中。
- 数据库代理将 SQL 语句发送到相应的数据库节点,并将结果合并后返回给客户端。
 微信
微信- 支付宝






