
使用 CUDA 部署 LLM、TTS、ASR 三种类型的开源模型
前言
目前 AI 的入门门槛已大幅降低,对硬件性能的要求也不再严苛。所以想写一篇基于如何使用 NVIDIA 显卡来跑目前比较热门的模型,这篇文章我会从环境配置到模型部署,每个流程都尽量细致入微,让一个从没接触过 ai 的人可以完成,如果你觉得有什么地方可以优化修改,欢迎评论留言,我也会不断完善文章,帮助更多有兴趣的人部署属于自己的模型。
PS:虽然入门门槛是降低了,但并不是完全没有,所以在你开始前,你需要确保你有这些东西:一张NVIDIA的显卡(性能越高越好);一个可以访问外网的魔法(需要下载的东西有不少都需要外网);一点编程基础(当然我们会通过 Python 来完成模型的部署)
前置准备
因为 CUDA 只有 NVIDIA 显卡有,因此首先需要拥有一张 NVIDIA 显卡(本人也因此把 7900XTX 换成了 5080),下面简单介绍一下本次的开发环境,仅供参考,若想要自行变更版本一定要将 CUDA、PyTorch、cuDNN 之间的关系对应上。
PS:PyTorch 在 2.7.0 版本才支持 Blackwell 架构,因此对于 50 系显卡,最低的 PyTorch 也不能低于这个版本!
- 操作系统:win11 23H2
- 显卡:RTX 5080
- 驱动版本:576.40
- CUDA 版本:12.8.1
- PyTorch 版本:2.7.0 & 2.7.1(在这篇文章完成前,又出了 2.7.1😭,不过是小版本不用太在意)
- cuDNN 版本:8.9.6
- PyThon 版本: 3.10.6
在开始使用 AI 模型前,我们需要了解三个东西:CUDA、cuDNN 和 PyTorch 。正是这三者的协同工作,GPU 的性能才能被完全发挥出来。形象一点的比喻就像是一个赛车比赛,GPU,也就是显卡,是赛车引擎,拥有强大的马力。而 CUDA 则像是赛车的驾驶系统,能让我们自由的控制赛车。cuDNN 则类似于赛车的调校工具,能够优化深度学习运算过程,从而提高性能。PyTorch 就像我们的车队,负责制定赛车的策略,对赛车的各项微调。后面我们会在每个部分进行更细致的讲解,这里只需要了解他们之间的关系即可。
CUDA 环境
在 AI 方面,相信各位听过最多的词应该就是 CUDA 了,那 CUDA 具体是什么?CUDA 是一个并行计算平台和编程模型,支持开发者使用 C++ 和 Fortran 等语言编写程序,并直接在 GPU 的众多核心上运行,以实现通用计算的加速。以入门的 RTX 5060 为例,其 CUDA 核心数为 3840。再加上 GPU 能进行并行计算,速度远超 CPU 的串行计算,因此建议优先使用 GPU 进行模型训练或推理,避免依赖 CPU 。下面就进入 CUDA 的安装环节:
下载 CUDA 安装包
安装 CUDA 前,我们要知道自己 GPU 支持的最高版本,在 cmd 中输入 nvidia-smi 查看自己显卡最高支持的版本,这里右上角显示的 CUDA 版本是你的驱动程序能够支持的最高 CUDA 版本,不是你当前安装的 CUDA 版本!!!
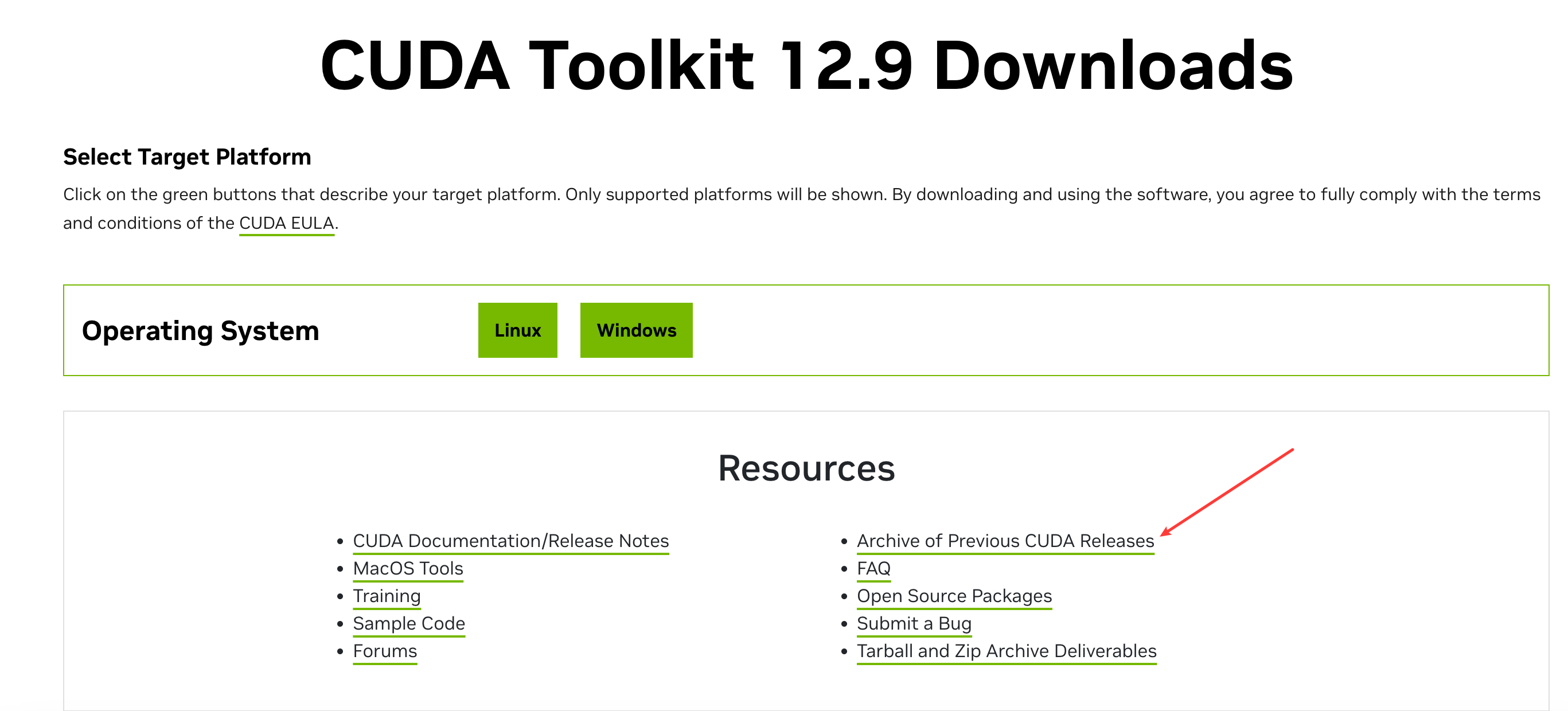
进入 NVIDIA CUDA CUDA 下载页面,该页面默认下载的是最新的,这里我选择手动下载 12.8.1 的版本,点右下角的 Archive of Previous CUDA Releases
继续点击 CUDA Toolkit 12.8.1。

选择对应平台及系统,记得选本地下载。

安装 CUDA
打开 CUDA 的安装程序,会让你选一个目录,这个目录只是个临时安装目录,后面还会让你选一个真正的安装目录,安装完成后临时文件会自动清除。
在安装选项我们选择自定义安装,只安装 CUDA 即可,把其他的✅去掉。
这里我已经安装完了,就不再安装一遍了,下一步你就能看到 CUDA 的真实安装目录,不过建议不要改动(就是 C 盘会吃紧,安装一个 CUDA 版本大概要占 4G 左右的大小)。
验证安装
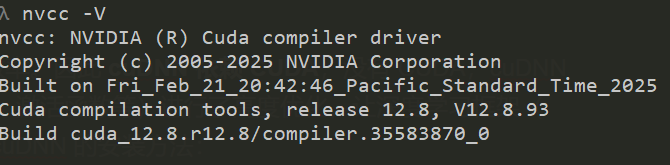
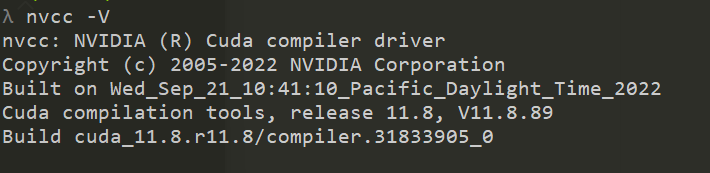
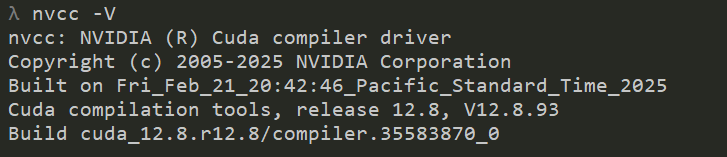
使用 nvcc -V 检测 CUDA 版本,这里显示的是 当前激活的 CUDA 版本。
cuDNN 环境
cuDNN 是 NVIDIA 提供的一个深度学习加速库,用来加速深度学习的训练与推理效率。因此 cuDNN 依赖 CUDA,没有 CUDA,cuDNN 是无法运行的。cuDNN 内部针对深度学习中常见的运算(如卷积、池化、归一化、激活函数等)进行了高度优化,让深度学习框架( PyTorch)不必从头实现这些底层加速算法。因此强烈建议安装 cuDNN。以下是 cuDNN 的安装方法:
PS:下载 cuDNN 需要注册英伟达账号并且成为开发者,开发者验证也很简单,随便填点信息就可以了
下载 cuDNN 安装包
进入 NVIDIA cuDNN cuDNN 下载页面,下载对应版本的 cuDNN 包,因为我刚刚安装的是 CUDA12.8.1,所以下载第一个包即可。注意一定要和你的 CUDA 版本对应。

安装 cuDNN
下载完成后解压,会得到一个文件夹。因为 cuDNN 采用插入式安装方式,需将解压后的文件手动复制到 CUDA 的安装目录中以完成安装。
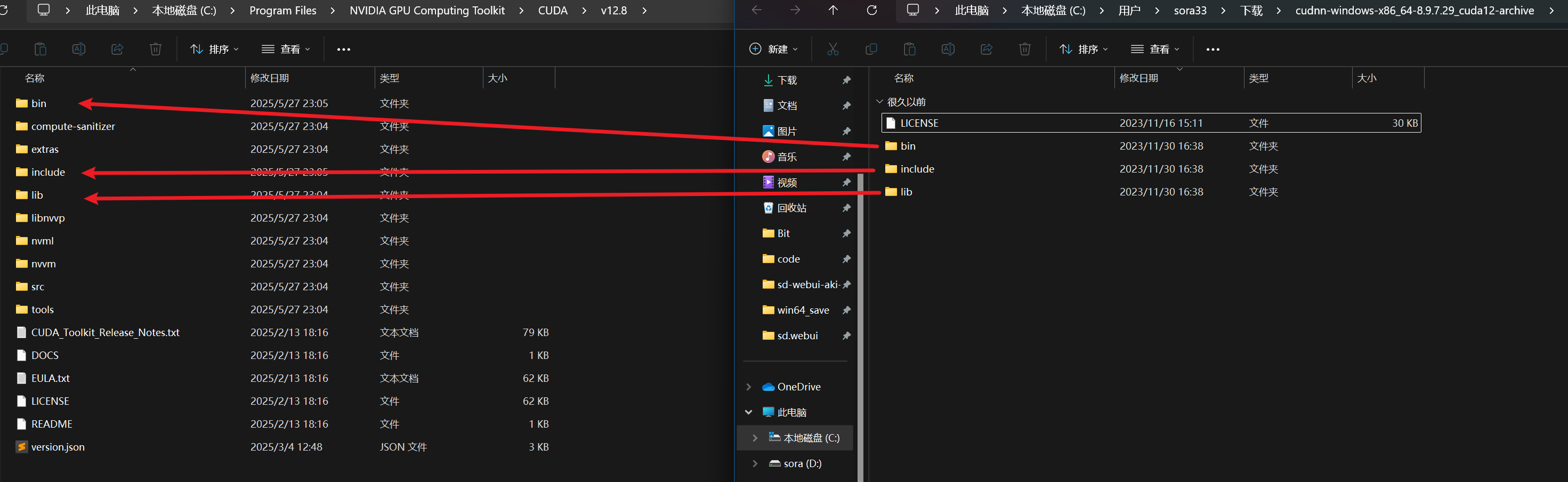
如果你 CUDA 安装在 C 盘,那么对应的安装目录在 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA 下, 找到安装的版本,如 v12.8,将 cuDNN 解压后对应名称的文件夹(bin, include, lib)下的内容,分别拷贝到 CUDA 安装路径下同名的文件夹内。
如图所示,将 cuDNN 的三个文件夹内的文件拷贝到对应 CUDA 的安装目录内。
PyTorch 环境
Pytorch 是 Meta 开发的深度学习框架,目前使用非常广泛。它提供了构建和训练神经网络所需的高级接口、张量运算等功能,结合 CUDA 和 cuDNN 可显著提升模型训练与推理速度。
CUDA 和 cuDNN 的安装是系统层面,它们会设置环境变量,系统中任何兼容的程序都可以调用。而 PyTorch 本身是一个 Python 库,与大多数 Python 包一样,是基于项目安装的,因此在后面创建项目时我们再安装 PyTorch,在此之前,我们要先确定使用的 PyTorch 版本。
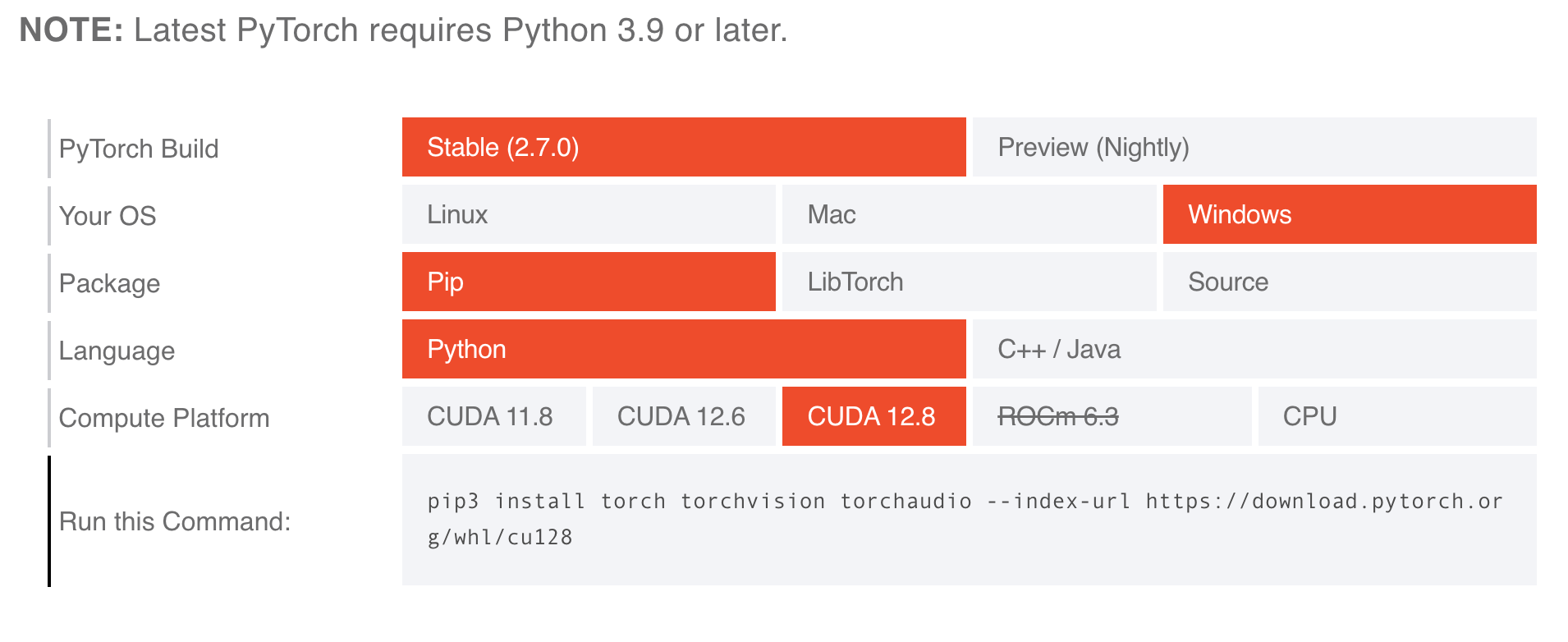
打开 PyTorch 页面,目前最新版本为 2.7.0 且需要 Python3.9 以上,支持的 CUDA 版本为 11.8、12.6、12.8。
选择好对应的平台以及 CUDA 版本,下面就是对应的 pip 安装命令,提前保存好,后面会使用到。
其他版本的 PyTorch 安装命令在该页面查看: PyTorch 历史版本
PS:如果你是 RTX50 系的显卡或者是其他 Blackwell 架构的计算卡,那么能选的 PyTorch 版本只有 2.7.0 及以上
Transformer
Transformer 我觉得也是一个很重要的东西,这里简单说明一下吧。对于玩游戏且喜欢了解硬件的人来说,肯定知道 DLSS4 的模型从 CNN 卷积神经网络升级成了 Transformer 模型,表现在游戏上,就是画面清晰度大幅上涨,原本 CNN 模型的质量档现在 Transformer 使用性能档就可以达到。
Transformer 出现前,AI 主要依赖两种架构,RNN(循环神经网络)和 CNN(卷积神经网络),前者像流水线一样处理信息,速度慢且随着序列长度的增加,模型会变得非常不稳定。后者擅长处理局部特征,难以处理序列信息。因此 RNN 适合处理序列数据(文本、语音),CNN 适合处理图像数据。而为了解决这些架构的缺点,Transformer 模型出现了,凭借强大的自注意力机制和并行化能力,成为处理序列和非序列数据的统一架构。解决了 RNN 和 CNN 的局限性。
Transformer 本身是一个神经网络架构设计方案。最初由 Google 团队提出,后来 Hugging Face 基于 Transformer 架构开发设计了 transformers 开源库,内部封装了大量训练好的模型。Transformer 的核心设计是自注意力机制,简单来讲就是处理每个词语时,可以理解句子中词语之间的关系和整句话的含义,例如我输入:’苹果手机很贵,但买它的人很多’,模型能通过自注意力机制理解这里的 “苹果” 指的是 “苹果手机”,而 “它” 指的也是 “苹果手机”,而非可食用的水果。
说了这么多,那么 Transformer 具体扮演者什么角色呢?它是现代 AI 的通用计算引擎,因为可以一次性理解整个输入内容,并捕捉全局关联关系和上下文信息,实现对数据的深刻理解。目前几乎所有现代 AI 模型都在使用 Transformer 架构。我们也需要借助 Hugging Face 的 transformers 开源库来驱动我们的开源模型,使得模型可以更高效的处理和理解复杂数据。
多个 CUDA 版本之间的切换
有时项目需要特定 CUDA 版本支持,涉及 CUDA 版本切换,要做到这一点,直接通过系统的环境变量就可以控制 CUDA 版本。
例如我现在本机的 CUDA 版本是 12.8,我想切换到 11.8。如果你已安装 CUDA 11.8,可直接进入下一步,否则请前往官网下载对应版本的 CUDA。安装时系统会自动按版本创建文件夹,无需手动更改路径。随后还需下载对应版本的 cuDNN,并将其文件复制到对应的 CUDA 安装目录中。此时 CUDA 版本就会自动变为 11.8。
那么要如何变回到 12.8 呢,很简单,修改系统的环境变量,将 12.8 的 CUDA 环境变量放到 11.8 的前面,保存,退出。查看 CUDA 版本,版本变为 12.8。

PS:当你切换了 CUDA 版本后,如果你之前项目里的 PyTorch 是针对特定 CUDA 版本编译的(例如之前用的PyTorch for CUDA 12.8),那么当你切换到了另一个 CUDA 版本(例如 11.8),这个 PyTorch 版本可能无法正常使用 GPU。所以需要提前确保 PyTorch 版本与当前激活的 CUDA 版本兼容,或者重新安装对应 CUDA 版本的 PyTorch。(当然你也可以再切换回当前项目使用的 CUDA 版本)
模型部署实践
接下来,我们会部署 LLM(大型语言模型)、ASR(自动语音识别) 和 TTS(文本转语音) 三种类型的模型,帮助大家快速部署和使用开源模型。每个模型都将使用独立的 Python 环境,确保依赖隔离。使用 uv 作为环境管理工具,比传统的方式相比,有更快的依赖解析和安装速度,推荐可以用一用,uv 可以在 Powershell 内执行 powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex" 来完成安装。
如果不想用 uv 的也可以自己手动管理环境,以下是一些基本命令对照。
| 传统命令 | uv 对应命令 | 说明 |
|---|---|---|
| python -m venv | uv init <项目名> | 创建虚拟环境 |
| pip install | uv add / uv pip install | 安装依赖包 |
| python main.py | uv run main.py | 运行项目 |
PS:下面使用的模型以及模型的调用方式仅供参考,具体如何使用请参考模型页面提供的方式。
CUDA 环境验证
在开始模型部署前,我们需要验证 CUDA 环境是否正确配置。下面的脚本将检查你的 PyTorch 是否能正常使用 GPU。
1 | 创建Python版本为 3.10.6 的项目 |
执行下面代码,测试是否可以正确读取到 CUDA。
1 | import torch |
如果正确读到了 CUDA,那么输出信息会是这样:
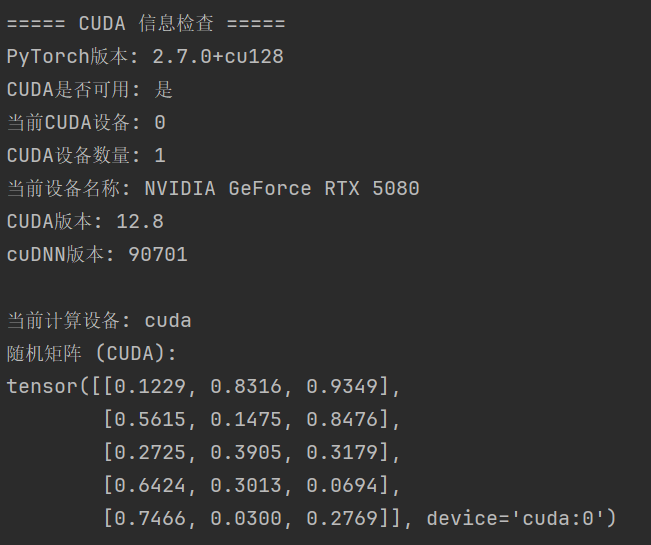
至此,我们就可以进入到部署模型的环节了。
认识 Hugging Face 与下载模型
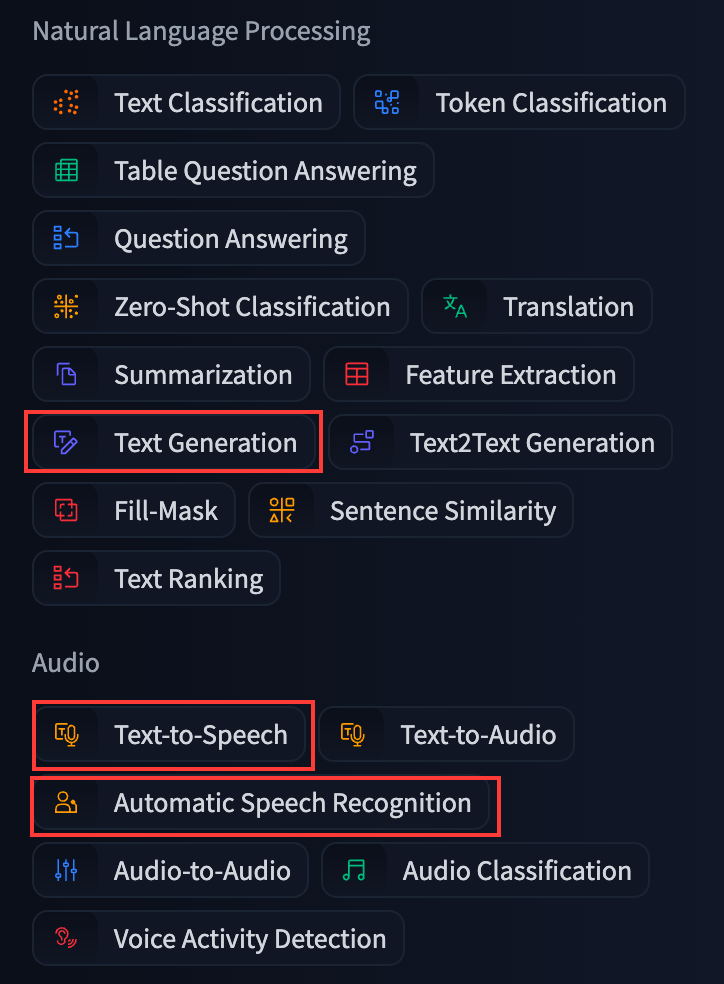
进入 Hugging Face 模型排行榜 页面,注册 Hugging Face 账号后,可以下载各种开源模型。左边可以筛选分类,而本次我们要使用的三个模型会从 Text Generation、Text-to-Speech、Automatic Speech Recognition(对应模型类型为llm、tts、asr) 三个分类中选出。
LLM 模型(大语言模型)
大型语言模型(Large Language Models,LLM) 指的是参数量巨大、在海量文本数据上进行预训练的深度学习模型。核心能力在于理解和生成人类语言。本次我们以 DeepSeek-R1-Distill-Qwen-1.5B 来做示例模型,这个模型参数只有 1.5B,即使显存只有 4GB,也无需量化即可直接运行。
进入 DeepSeek-R1-Distill-Qwen-1.5B 页面,将 Files and versions 中的文件全部下载到本地。
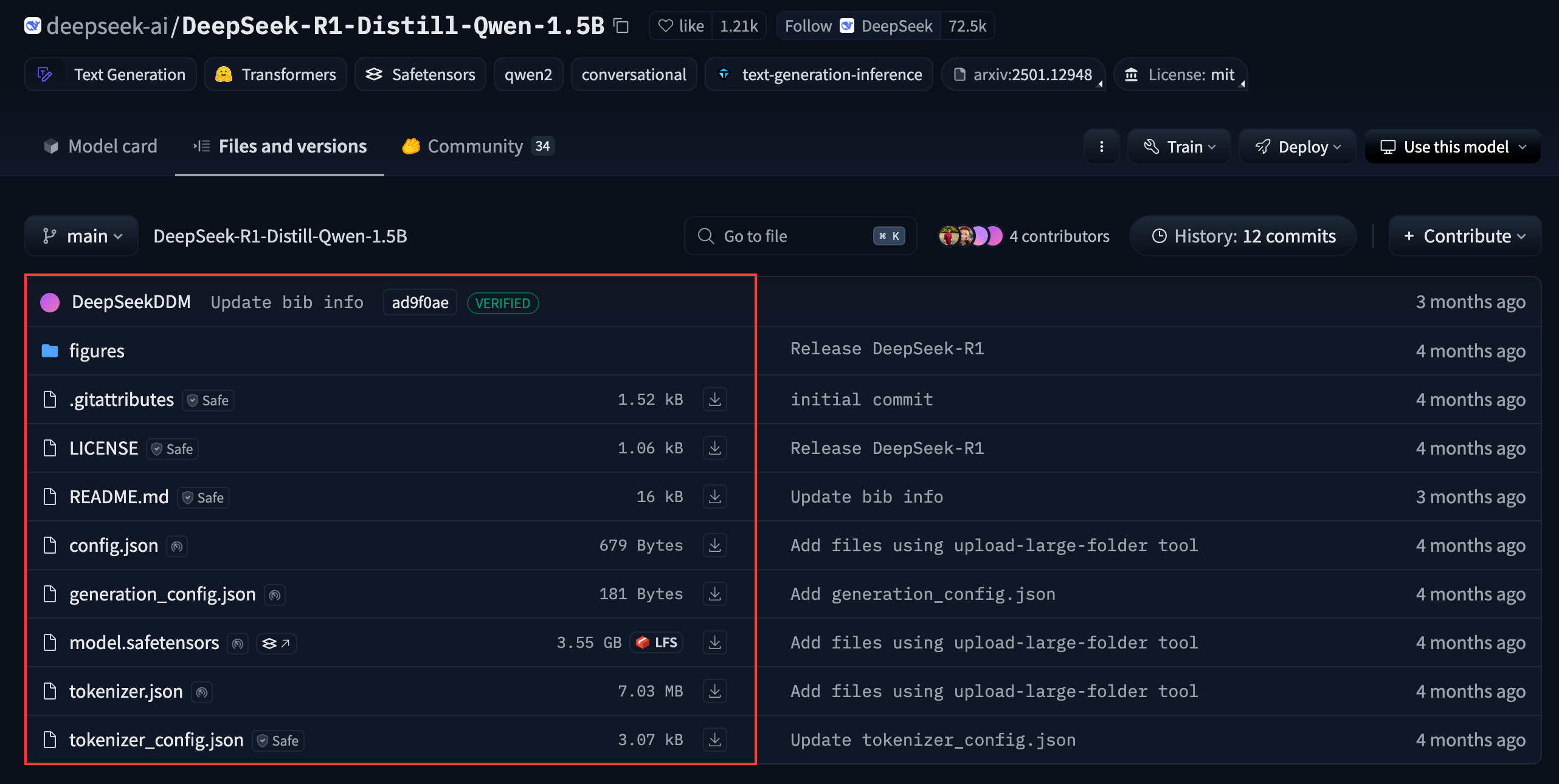
创建一个 Python 项目,Python 版本为 3.10.6。
1 | # 初始化项目 |
安装 PyTorch 和 transformers 依赖。
1 | 安装torch(注意 CUDA 版本,要和你的版本对应上。或者用你之前复制的 PyTorch 安装命令) |
将我们刚刚下载的模型文件放到文件夹内并移动到项目根目录下。
主代码如下,大部分的说明我都用注释标注了,只需要配置 main 方法的 message 参数就可以使用。这里需要说明的一点,由于该模型本身采用 bfloat16 精度训练且未进行量化处理,因此推荐使用相同精度加载模型。
1 | from transformers import AutoTokenizer, AutoModelForCausalLM, TextStreamer |
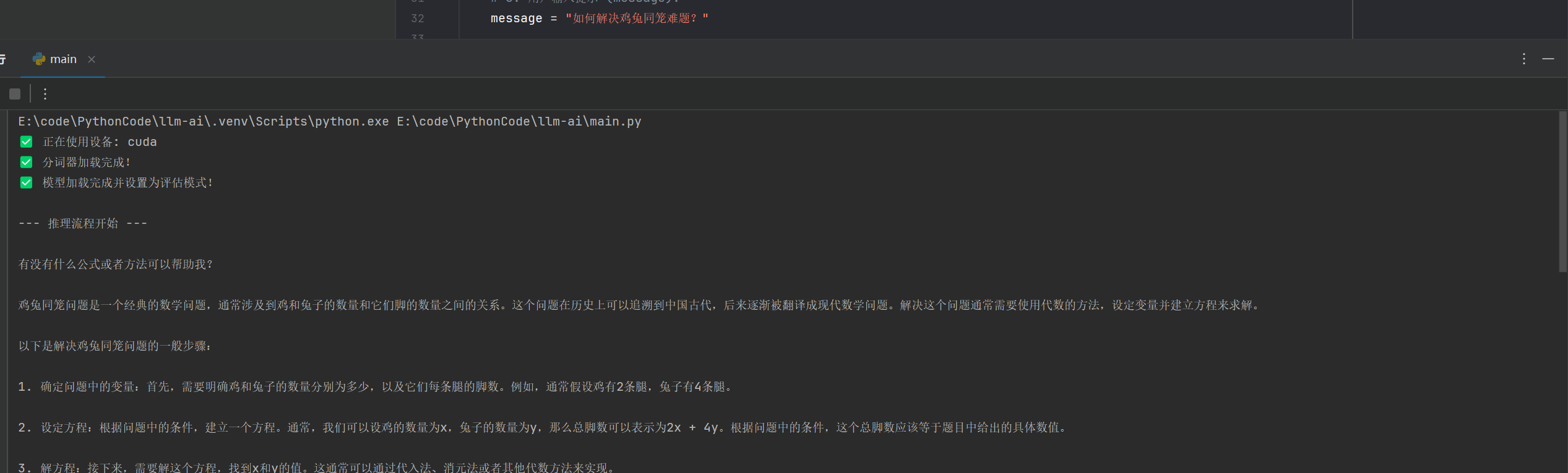
我这里问了一个经典的数学问题,但毕竟是 1.5B 的参数大小,质量肯定没有那么好,不过作为本地的小模型已经够用了。
TTS 模型(文本转语音)
文本转语音(Text-to-Speech,TTS) 可以将文本转化为自然的人类语音,通过声学建模、音色合成等映射语言学特征至声学参数,实现语音合成的技术。我们使用 coqui-tts 这个 TTS 模型来进行演示。
创建一个 Python 项目,Python 版本为 3.10.6。
1 | 初始化项目 |
安装 torch 和 coqui-tts 依赖。本次无需安装 transformers 库,因为 coqui-tts 已对我们使用的 xtts_v2 模型进行了专门的封装和优化。
1 | 安装torch(注意 CUDA 版本,要和你的版本对应上。或者用你之前复制的 PyTorch 安装命令) |
若安装
TTS时遇到以下问题,通常是 C++ 版本过低所致,打开后面那个链接,下载 vs 的安装工具。
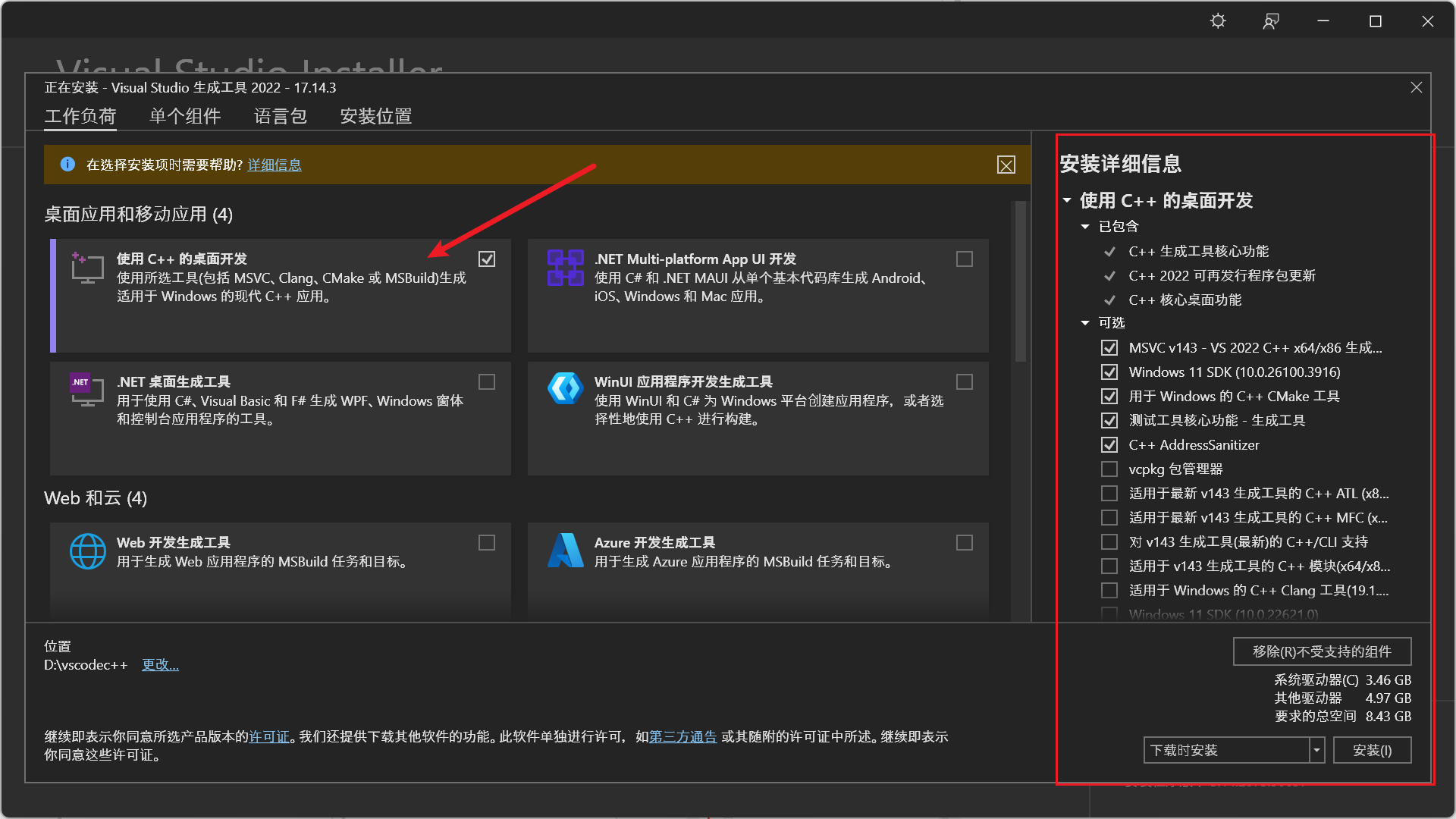
打开 vs 安装工具后,选择
C++的桌面开发,右边还必须勾上前五个可选包,安装完成后,这个问题就解决了。(多少有点恶心了,明明只是一个组件,必须多下载 8G 左右的东西,就算手动选择了 D 盘,也会在 C 盘留下 3G 左右的💩,那为什么还要用这个 TTS 模型呢,因为这个模型可以直接克隆自己的声音读取输入文本,比其他的模型更有意思点)

继续安装对应语言的字典,如果你想合成中文语音,那么请安装 pypinyin 字典库,想合成日文语音安装 unidic-lite 库,当然也可以 2 个都安装。
1 | 汉语字典 |
最后我们需要准备克隆音频以及启动模型的代码,提前准备 1 个 5-10 秒的纯人声 wav 文件,这里我推荐一个很好用的网站,可以免费提取人声:vocalremover。提取完成后,在项目根目录创建一个 sample 文件夹,放到里面。项目结构如下:
首次运行会下载 2G 大小的模型,代码内需要配置的地方只有 main 方法中的参数,并且都用注释进行了标注,按照自己的需求更改即可。
1 | import torch |
启动后,大概 1 分钟左右就可以输出结果文件,默认会保存在项目根目录,名字为 output.wav, 目前用下来,中文的生成要比日语的更好点。
ASR 模型(自动语音识别)
自动语音识别(Automatic Speech Recognition,ASR) 又称语音转文本(Speech-to-Text),是将人类语音转换为可读文本的技术。本次选择 openai 的 whisper-large-v3 模型来进行演示。
同样,我们需要创建一个新项目,Python 版本依旧使用 3.10.6。
1 | 初始化项目 |
安装 PyTorch 和 transformers 依赖
1 | 安装torch(注意 CUDA 版本,要和你的版本对应上。或者用你之前复制的 PyTorch 安装命令) |
创建完整后,准备几个音频素材,放到项目根目录下。
以下是具体代码,所有操作均已添加注释以便理解,只需配置一个要转录的 音频路径 就可以。与 TTS 模型类似,首次运行时会下载模型。
1 | import torch |
参数里我还加了一个是否带时间戳的格式输出,我个人觉得有时间戳更好点,当然你也可以选择关掉,下面是有无时间戳的对比。
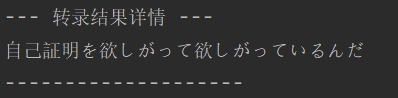

最后我试着转录一段动画,发现效果比想象的要好很多,不过也会把音频里的背景音乐,比如乐器、钢琴之类的一并转录,虽然不影响什么,但是在意的话可以在执行前,先把音频里的人声提取出来。红色字体的警告属于依赖包内部的代码,我们不需要在意。

结束语
到这里所有的内容都结束了。从 CUDA、cuDNN 到 PyTorch 和 Transformer,本文详细介绍了环境配置和主流模型类型的部署实践。如果你在部署过程中遇到任何问题,或对文章有宝贵的建议,欢迎随时在评论区留言交流!
 微信
微信- 支付宝






