前言 最近发现了这个新框架,想着学习一下发现网上的教程几乎全是对官网的复制粘贴…… 很多细节要点都没有告诉你,很容易让人看的一头雾水,所以自己跟着官网文档做了一个示例 Demo,写个教程做记录,也分享给需要的各位(后面会使用 flex 指代 mybatis-flex、plus 指代 mybatis-plus)
常见问题 这里我把常见问题放在前面是因为有很多坑,所以我想先把我踩过的坑列出来,提前了解,不然后面问题很多不好解释。这些坑我也都是从官网找的对应解决方法,在这里放出来同时加深一下印象。
如何使用分页
以前我们 mybatis-plus 会搭配 pagehelper-spring-boot-starter 依赖来实现分页,但是使用 mybatis-flex 后,请注意,将分页依赖更换为 pagehelper 依赖 原因是 pagehelper-spring-boot-starter 依赖的 mybatis-spring-boot-starter 会使 flex 启动异常,导致查询时参数赋值不上,会产生《No value specified for parameter xxxx》错误。当然也可以使用自带的分页,本文使用自带的分页进行演示!!!
热部署产生的异常
在使用 selectOneByQuery 这个方法时,查询获取的对象不能成功转换为对应的实体类,报《ClassNotFoundException》错误,但返回的确实是对应类型。原因是启用了热部署造成的,解决办法也很简单,在 resource 下建立一个 META-INF 目录,新建文件命名 spring-devtools.properties,内容写入:
1 2 3 4 5 restart.include.mapper=/mapper-[\\w-\\.].jar restart.include.pagehelper=/pagehelper-[\\w-\\.].jar restart.include.mybatis-flex=/mybatis-flex-[\\w-\\.]+jar
启动报错 Property ‘sqlSessionFactory’ or ‘sqlSessionTemplate’ are required 添加 hikari 连接池依赖即可解决
SpringBoot2.x 版本:
1 2 3 4 5 <dependency > <groupId > com.zaxxer</groupId > <artifactId > HikariCP</artifactId > <version > 4.0.3</version > </dependency >
SpringBoot3.x 版本:
1 2 3 4 5 <dependency > <groupId > com.zaxxer</groupId > <artifactId > HikariCP</artifactId > <version > 5.0.1</version > </dependency >
如果使用的是 druid 数据库连接池,则需要添加数据源类型的配置 spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
为什么要使用 mybatis-flex? 这里我直接搬官网的说明了。简而言之,flex 相对于我们使用的 plus 而言,支持了多表查询!这是我认为很大的一个亮点;然后就是对于字段的更细一步的处理、自带多数据源切换、自带分批批量插入以及性能上的提升等等;代码写法也进行了更新,例如下图,flex 是内部使用 APT(Annotation Processing Tool)生成的字段,不容易出错且美观,而 plus 则是全程使用字符串完成。在性能上,根据官网的描述,flex 的查询比 plus 快了近 10 倍
功能或特点
MyBatis-Flex
MyBatis-Plus
Fluent-MyBatis
对 entity 的基本增删改查
✅
✅
✅
分页查询
✅
✅
✅
分页查询之总量缓存
✅
✅
❌
分页查询无 SQL 解析设计(更轻量,及更高性能)
✅
❌
✅
多表查询: from 多张表
✅
❌
❌
多表查询: left join、inner join 等等
✅
❌
✅
多表查询: union,union all
✅
❌
✅
单主键配置
✅
✅
✅
多种 id 生成策略
✅
✅
✅
支持多主键、复合主键
✅
❌
❌
字段的 typeHandler 配置
✅
✅
✅
除了 MyBatis,无其他第三方依赖(更轻量)
✅
❌
❌
QueryWrapper 是否支持在微服务项目下进行 RPC 传输
✅
❌
未知
逻辑删除
✅
✅
✅
乐观锁
✅
✅
✅
SQL 审计
✅
❌
❌
数据填充
✅
✅
✅
数据脱敏
✅
✔️ (收费)
❌
字段权限
✅
✔️ (收费)
❌
字段加密
✅
✔️ (收费)
❌
字典回写
✅
✔️ (收费)
❌
Db + Row
✅
❌
❌
Entity 监听
✅
❌
❌
多数据源支持
✅
借助其他框架或收费
❌
多数据源是否支持 Spring 的事务管理,比如 @Transactional 和 TransactionTemplate 等
✅
❌
❌
多数据源是否支持 “非 Spring” 项目
✅
❌
❌
多租户
✅
✅
❌
动态表名
✅
✅
❌
动态 Schema
✅
❌
❌
springBoot 引入 mybatis-flex 环境 下面开始说一下我这里所使用的环境:
Java:17
SpringBoot:3.0.5
mybatis-flex:1.7.6
mysql:8.0.33
我是基于 SpringBoot3.0.5 版本进行测试的,如果出现问题,首先排查版本,其次去官网的 faq 部分去排查。mybatis-flex 常见问题 ,还有问题可以在本文章下留言或者去 github 留言 mybatis-flex github 项目是 23 年 3 月左右开源的,是一个很年轻的项目,还需要大家多多使用,磨合一段时间
依赖 依赖我使用的都是最新版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-jdbc</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-devtools</artifactId > <scope > runtime</scope > <optional > true</optional > </dependency > <dependency > <groupId > org.projectlombok</groupId > <artifactId > lombok</artifactId > <optional > true</optional > </dependency > <dependency > <groupId > com.mybatis-flex</groupId > <artifactId > mybatis-flex-spring-boot-starter</artifactId > <version > 1.7.6</version > </dependency > <dependency > <groupId > com.mybatis-flex</groupId > <artifactId > mybatis-flex-processor</artifactId > <version > 1.7.6</version > <scope > provided</scope > </dependency > <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > <version > 8.0.33</version > </dependency >
配置 通过 mybatis-flex 属性配置各种内容,这里我配置了 2 个数据源,分别是 sora01 和 sora02。以往我们使用多数据源往往需要引入 dynamic 依赖,而现在直接内部集成了,这个就很棒了。后面的跟 mybatis-plus 是一样的,通过 mapper-locations 配置 mapper 文件地址,同时开启 sql 日志打印
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 server: port: 1234 mybatis-flex: datasource: sora01: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/sora33?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8 username: root password: root sora02: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/sora-xxl?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8 username: root password: root mapper-locations: classpath:mapper/**/*.xml configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
我们在选择数据源的时候有四种方式,分别是代码中使用、在类上或方法上使用@UseDataSource 注解以及直接在 Table注解上配置。四个配置的优先级如下:
1 `DataSourceKey.use()` > `@UseDataSource()在方法上` > `@UseDataSource()在类上` >`@Table(dataSource="...")`
同时,现在数据库和实体类字段之间的驼峰转换从以前的一刀切改为了表级别的粒度。
在 mybatis-plus 中,我们需要通过在配置文件内配置驼峰转换,这样我们一整个模块都会应用。
1 2 configuration: map-underscore-to-camel-case: true
而在 flex 中,我们可以直接在 Table 注解上配置是否启用驼峰转换,如下图则关闭驼峰转换(默认是开的)
1 @Table(value = "sora_user", camelToUnderline = false)
前置准备 首先是实体类,通过 Table注解标注表名,Id注解表明主键使用 lombok 生成 getset 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 @Data @Table("sora_user") public class User implements Serializable { @Id(keyType = KeyType.Auto) private String id; private String name; private String sex; private Date birthday; private String password; private String phone; private String email; private Integer roleLevel; private Date createTime; private String banned; private String disabled; }
之后我们需要让 mapper 接口实现 BaseMapper 接口并制定对应的实体类,如果是 plus 的话,还需要对 service 以及 service 实现类实现指定的接口和继承指定的类。
1 2 3 @Mapper public interface UserMapper extends BaseMapper <User> {}
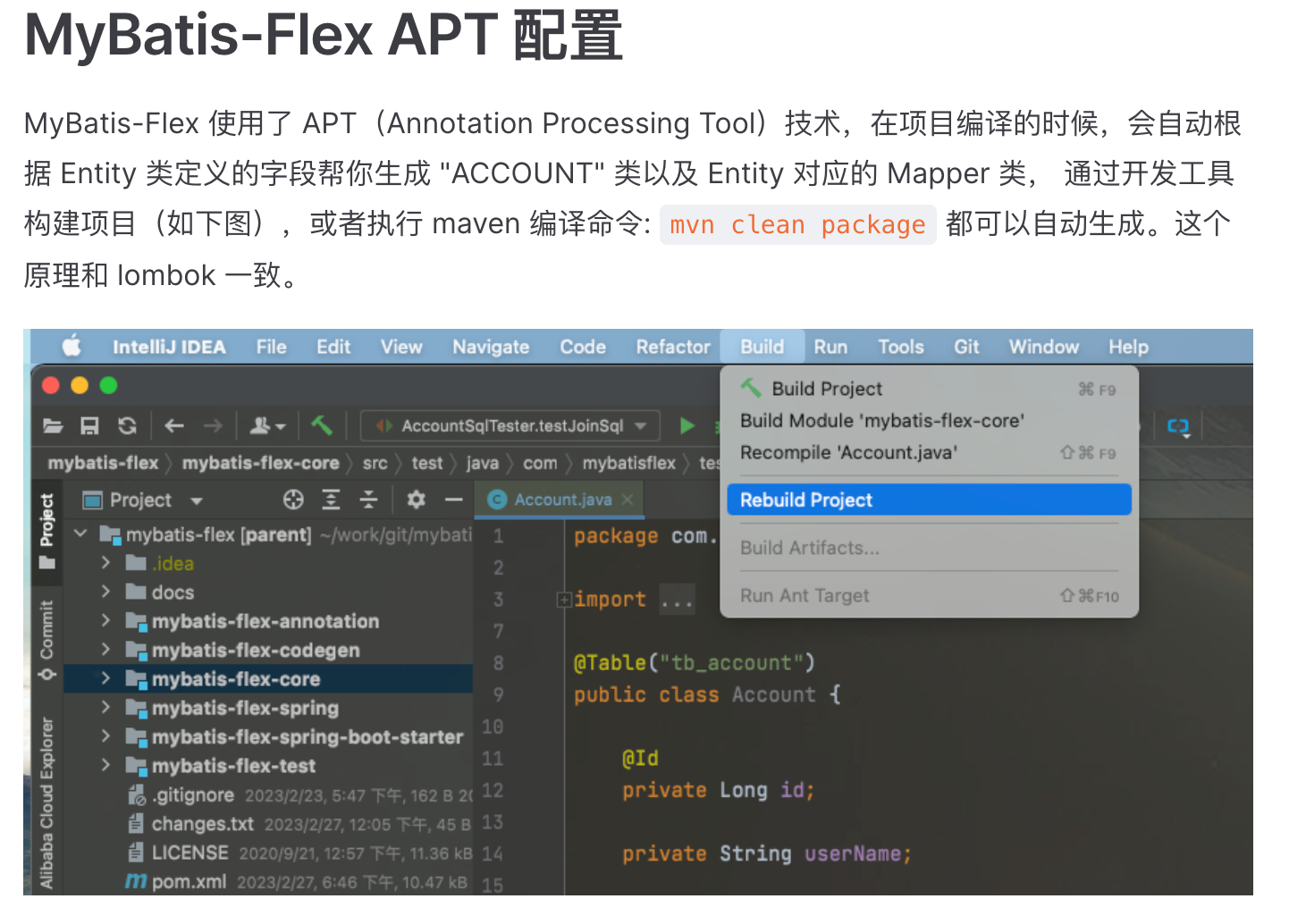
编译项目获取 APT 文件 注意: 我们上面说 flex 使用了 APT 技术。所以在使用之前必须先编译项目,官网给出的说明如下:
我习惯创建完实体类直接启动一次项目,这样更不容易出错,生成的 APT 文件在 target 文件夹下的 generated-sources 目录内。默认会在你原本的类名后面跟 Def
如果文件生成了但代码内使用不了参考下图内的解决办法
下面是 User 类生成后的文件,包含了当前类所有的字段。在后面拼接条件时,可以随意获取想要的字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 package com.sora.domain.table;import com.mybatisflex.core.query.QueryColumn;import com.mybatisflex.core.table.TableDef;public class UserTableDef extends TableDef { public static final UserTableDef USER = new UserTableDef (); public final QueryColumn ID = new QueryColumn (this , "id" ); public final QueryColumn SEX = new QueryColumn (this , "sex" ); public final QueryColumn NAME = new QueryColumn (this , "name" ); public final QueryColumn EMAIL = new QueryColumn (this , "email" ); public final QueryColumn PHONE = new QueryColumn (this , "phone" ); public final QueryColumn BANNED = new QueryColumn (this , "banned" ); public final QueryColumn BIRTHDAY = new QueryColumn (this , "birthday" ); public final QueryColumn DISABLED = new QueryColumn (this , "disabled" ); public final QueryColumn PASSWORD = new QueryColumn (this , "password" ); public final QueryColumn ROLE_LEVEL = new QueryColumn (this , "role_level" ); public final QueryColumn CREATE_TIME = new QueryColumn (this , "create_time" ); public final QueryColumn ALL_COLUMNS = new QueryColumn (this , "*" ); public final QueryColumn[] DEFAULT_COLUMNS = new QueryColumn []{ID, SEX, NAME, EMAIL, PHONE, BANNED, BIRTHDAY, DISABLED, PASSWORD, ROLE_LEVEL, CREATE_TIME}; public UserTableDef () { super ("" , "sora_user" ); } }
最终我们在代码内只需要引入就可以使用了,注意在代码内使用的时候必须全部为大写;
同时要注意驼峰,如果原始类为 User 则使用 USER;原始类为 sora_user_log 则使用 SORA_USER_LOG
1 2 3 4 5 6 7 import static com.sora.domain.table.SoraUserLogTableDef.SORA_USER_LOG;import static com.sora.domain.table.UserTableDef.USER;QueryWrapper.create().select(USER.ALL_COLUMNS).where(USER.NAME.like("33" )) QueryWrapper.create().select(SORA_USER_LOG.ALL_COLUMNS).where(SORA_USER_LOG.NAME.like("33" ))
查询 第一个查询示例 这里先写一组简单的示例,包含了 where动态条件拼接、and与or的用法、分页查询
首先是查询的发起,直接使用 QueryWrapper.create() 后面拼接条件即可。下面我对每个条件进行解释说明
select:sql 返回的列,这里我使用 ALL_COLUMNS 表示返回所有的列
where:在 where 内,我们可以直接使用字段名和值去进行匹配,也可以动态拼接,通过后面的 when 参数内的值决定是否拼接该条件,为 true 则拼接
and:和 where 用法一样,条件的拼接。和 where 一样,如果条件的值为 null,则不会拼接该条件
or:对数据进行 or 匹配。注意 or 语句里面可以继续嵌套 or,这样拼接出来的语句会带上括号。下面会展示不嵌套的 sql 帮助理解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @UseDataSource("sora01") public Result select () { QueryWrapper queryWrapper = QueryWrapper.create() .select(USER.ALL_COLUMNS) .where(USER.NAME.like("33" )) .and(USER.NAME.like("test" ).when(false )) .and(USER.BANNED.eq(null )) .or(USER.SEX.eq("1" ).or(USER.SEX.eq("0" ))); Page<User> paginate = userMapper.paginate(1 , 2 , queryWrapper); List<User> userList = userMapper.selectListByQuery(queryWrapper); System.out.println("分页查询结果:" + paginate); System.out.println("普通查询结果:" + userList); return Result.success(paginate); }
拼接出的 sql 为
1 SELECT * FROM `sora_user` WHERE `name` LIKE '%33%' OR (`sex` = '1' OR `sex` = '0' )
现在我把 or 语句的嵌套取消
1 2 3 4 5 6 7 QueryWrapper queryWrapper = QueryWrapper.create() .select(USER.ALL_COLUMNS) .where(USER.NAME.like("33" )) .and(USER.NAME.like("test" ).when(false )) .and(USER.BANNED.eq(null )) .or(USER.SEX.eq("1" )) .or(USER.SEX.eq("0" ));
可以看到,取消嵌套的 or 是不带括号的
1 SELECT * FROM `sora_user` WHERE `name` LIKE '%33%' OR `sex` = '1' OR `sex` = '0'
分页的结果如下,获取到正确的总数及对应页数的数据
普通查询则查询出所有数据
第二个查询示例 第二个查询包含两表联查、自定义展示列、外键连接以及条件筛选过滤。因为两表联查返回的结果我们需要一个对象来接受,这里我就创建了一个 SoraUserLogRes 对象,同时创建对应的 mapper,使用该对象来接受两表联查的结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @UseDataSource("sora01") public Result select () { QueryWrapper queryWrapper = QueryWrapper.create() .select(USER.ID.as("id" ), USER.NAME.as("name" ), SORA_USER_LOG.LOG_TYPE.as("logType" ), SORA_USER_LOG.CLASS_PATH.as("classPath" ) ) .from(USER) .where(USER.NAME.eq("sora33" )) .innerJoin(SORA_USER_LOG) .on(USER.ID.eq(SORA_USER_LOG.USER_ID)); List<SoraUserLogRes> userList = soraUserResMapper.selectListByQuery(queryWrapper); return Result.success(userList); }
我们直接看结果,成功接收到两表联查的结果,并且只有我们需要的四个列有值
第三个查询示例 第三个查询主要展示聚合函数以及分组。这里按照性别分组,将聚合函数计算的结果使用 AS 重命名为 email,这样就会把结果赋值到实体类的 email 字段上
1 2 3 4 5 6 7 8 9 @UseDataSource("sora01") public Result select () { QueryWrapper queryWrapper = QueryWrapper.create() .select(USER.SEX, count(USER.NAME).as("email" )) .groupBy(USER.SEX); List<User> userList = userMapper.selectListByQuery(queryWrapper); return Result.success(userList); }
可以得出性别为男的有 1 人,女的为 2 人
链式查询 通过 QueryChain 并配置对应 mapper 即可进行链式查询
1 2 3 4 5 6 7 8 9 10 11 @UseDataSource("sora01") public Result select () { List<User> userList = QueryChain.of(userMapper) .select(USER.ALL_COLUMNS) .where(USER.NAME.like("33" )) .and(USER.BANNED.eq(null )) .and(USER.SEX.eq("1" ).or(USER.SEX.eq("0" ))) .list(); return Result.success(userList); }
新增 新增一条数据 具体代码如下,和 plus 一样,我们需要创建一个对象,之后调用 insert 方法插入即可(这里的 insertSelective 方法和 insert 区别在于 insert不会忽略null,所以默认值会被覆盖掉,我们在创建表时如果表有默认值最好使用 insertSelective 方法来进行插入)
1 2 3 4 5 6 7 8 9 10 11 12 13 @UseDataSource("sora01") public Result insert () { User user = new User (); user.setEmail("xxx@email.com" ); user.setName("com" ); user.setPassword("pwd" ); user.setEmail("xxx@email.com" ); user.setPhone("19935768765" ); user.setId(IdUtil.getSnowflakeNextIdStr()); int insert = userMapper.insertSelective(user); return Result.success(insert); }
添加后的数据
批量新增 新增数据我们可以调用 insertBatch 接口,并且可以控制每次新增的数据个数
这里我创建一个 10w 数据量的集合,并演示一次性插入和分 10 次插入的效率
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 @UseDataSource("sora01") public Result insert () { List<User> userList = IntStream.range(0 , 100000 ) .mapToObj(i -> { User user = new User (); user.setEmail("xxx@email.com" ); user.setName("com" + i); user.setSex("9" ); user.setPassword("pwd" ); user.setPhone("19935768765" ); user.setEmail("xxx@email.com" ); user.setId(IdUtil.getSnowflakeNextIdStr()); return user; }) .toList(); StopWatch stopWatch = new StopWatch (); stopWatch.start(); int insert = userMapper.insertBatch(userList); int insertByTen = userMapper.insertBatch(userList,userList.size() / 10 ); stopWatch.stop(); logger.info("添加[{}]条数据,耗时[{}]MS" , userList.size(), stopWatch.getLastTaskTimeMillis()); return Result.success(insert); }
首先来看一下一次性插入的时间,耗时 46 秒
下面是分 10 次插入的时间,共执行了 10 次 sql,耗时 6 秒,速度快了近 8 倍。所以对于数据量大的插入,分批插入效果会更好
修改 第一种方式 我们需要先获取修改的对象,使用 UpdateChain 对象,通过链式调用设置好我们要修改的值,最后通过 where 设置条件,最后调用 update 方法完成修改。
setRaw 和 set 的区别:setRaw 是 sql 拼接,下面 Birthday 字段和 email 字段都是通过 sql 拼接赋值,而 set 相当于占位符赋值。例如 sex 和 phone,phone 这里我使用 add 方法,在原本 phone 的基础上 + 100
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @UseDataSource("sora01") public Result update () { QueryWrapper wrapper = QueryWrapper.create() .where(USER.ID.eq("1743103286858469376" )); User user = userMapper.selectOneByQuery(wrapper); boolean update = UpdateChain.of(user) .setRaw(USER.BIRTHDAY, "now()" ) .setRaw(USER.EMAIL, "CONCAT(email,'update')" ) .set(USER.PHONE, USER.PHONE.add(100 )) .set(USER.SEX, "1" ) .where(USER.ID.eq("1743103286858469376" )) .update(); return Result.success(update); }
第二种方式 和第一种方式相比,第二种方式只需要根据 id,通过 flex 的 UpdateEntity 类创建对象即可进行修改
1 2 3 4 5 6 7 8 9 10 11 12 @UseDataSource("sora01") public Result update () { User user = UpdateEntity.of(User.class, "1743143044292800512" ); UpdateWrapper.of(user) .setRaw(USER.BIRTHDAY, "now()" ) .setRaw(USER.EMAIL, "CONCAT(email,'update')" ) .set(USER.PHONE, USER.PHONE.add(100 )) .set(USER.SEX, "1" ); int update = userMapper.update(user); return Result.success(update); }
修改后的数据:
第三种方式 通过 update 方法,传入一个包含主键 id 的对象完成修改
1 2 3 4 5 6 7 8 @UseDataSource("sora01") public Result update () { User user = new User (); int update = userMapper.update(user); return Result.success(update); }
删除 删除我们一般根据 id 删除,也可以自己配置条件,根据条件进行删除。
1 2 3 4 5 6 7 8 9 10 11 12 13 @UseDataSource("sora01") public Result delete () { QueryWrapper queryWrapper = QueryWrapper.create(); queryWrapper.where(USER.SEX.eq(2 )); userMapper.deleteByQuery(queryWrapper); userMapper.deleteById("1743103286858469376" ); userMapper.deleteByCondition(USER.SEX.eq(0 )); return Result.success(); }
批量删除 1 2 userMapper.deleteBatchByIds(new ArrayList <>());
结束语 对 flex 的初步认识与使用到这里就结束了,当然 flex 还有很多强大的功能,这里贴上官网地址
mybatis-flex 官网
QueryWrapper 进阶












 微信
微信





