
基于 ollama 从零部署大语言模型
前言
环境介绍:使用的 Python 版本为 3.12.4 且需要魔法网络,对电脑性能有一定需求(但也没那么离谱)
相信不少人已经体验过 Ai 带来的便利了,甚至在工作上使用 Ai 加以辅助。本文是对那些对 Ai 产生兴趣且希望在自己的设备上实际运行大语言模型的人而准备,希望可以通过这篇文章来让更多人认识和了解 Ai。本文是基于 ollama 创建和部署大语言模型,下面就开始进入正文。
ollama 是什么?
ollama 是一个管理大语言模型的工具,帮助我们在本地快速创建、部署、使用大语言模型。它本身并不是一个大语言模型!还有一个名词 llama,它跟 ollama 很像,但是区别可就大了。llama 是由 Meta 开发的大语言模型,所以我们可以使用 ollama 加载 llama 这样的大语言模型。
安装 ollama
进入 ollama 官网,点击下载按钮,安装到自己电脑上即可。安装完成后可以使用 ollama -v 测试是否安装成功

使用 ollama 运行 llama3.2 模型
我们先简单启动一个模型进行测试,我们以 Meta 最新的 llama3.2 的 1b 模型为例,执行下面命令可以自动安装并启动 llama3.2 模型。
1 | ollama run llama3.2:1b |
在模型启动后,我们可以进行一些简单的对话,不过最好使用英文,因为 llama3 目前还不支持中文,简单的体验完成后,我们继续准备通过 ollama 部署各种开源模型到本地。
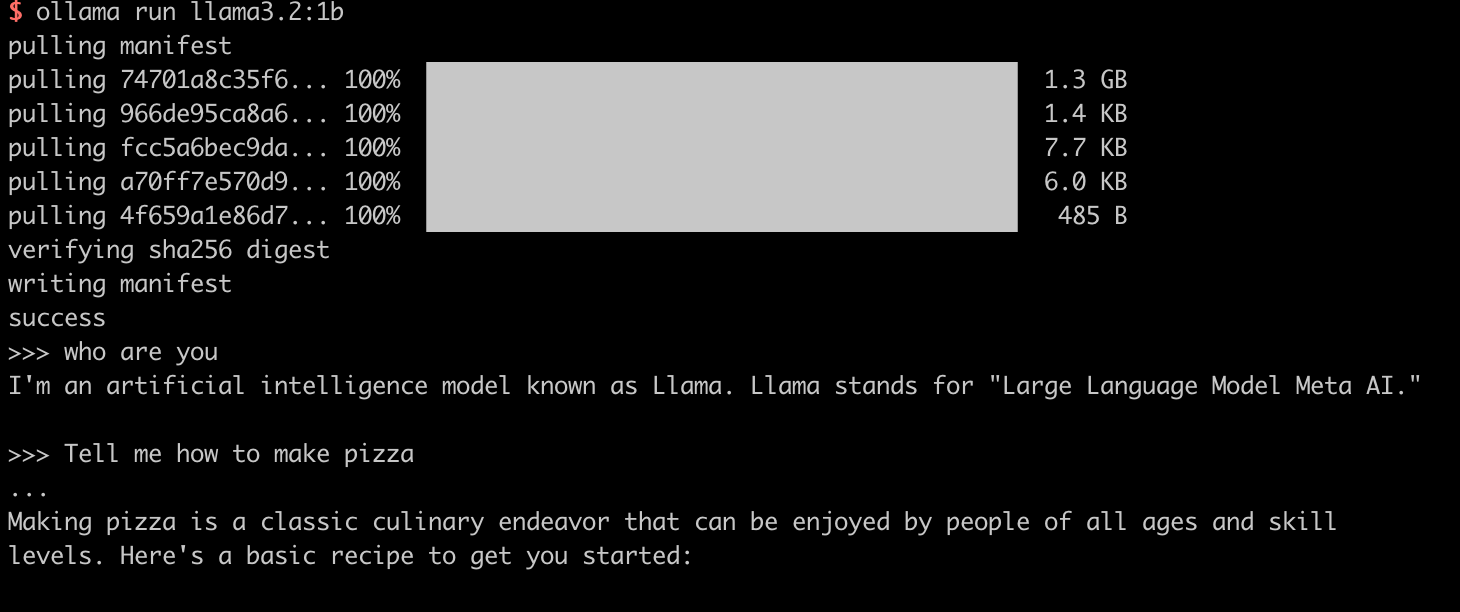
ollama 常用命令:
1 | 查看模型列表 |
在 Huggingface 上选择模型
Huggingface 是一个集开源工具、模型库、数据集为一体的平台,提供了 transformers 库、Hugging Face Hub 等功能,其中 Hub 是一个类似于 GitHub 的代码托管平台,我们可以在上面下载开源的模型、数据集使用。本次我们就要通过 Huggingface 下载模型,首先进入 Hugging face 模型页
以大语言对话模型为例,在左侧筛选,仅选中 Text Generation
继续在搜索框中输入 Qwen,选择 Qwen/Qwen2.5-Coder-7B-Instruct,也就是阿里的通义千问模型,Coder 是编程特化型,和基础版相比提升了编程性能。下面是模型首页 Huggingface-Qwen2.5-7B

下载模型
现在模型的主要存储格式主要有 gguf 和 safetensors,gguf 采用了二进制格式编码,优化了数据结构和资源占用,可以直接通过 ollama 加载。safetensors 则是未经过量化、更侧重于文件加载速度和安全的一种格式。
如果一个模型提供了 gguf 格式,我们可以直接下载下来,编写启动脚本完成模型创建,而 safetensors 格式则需要先将模型转变为 gguf 格式后再编写脚本创建。不管哪种格式,我们都需要先将模型下载下来,下面我们来看两种格式不同的下载方式。
gguf:
我们进入模型详情页后,点击 Files and versions,可以看到具体的文件,而且都有不一样的后缀,例如 Q3、Q4 等,这代表量化精度,这里先不介绍,后面会细说,目前先记住数字越大,精度越高。我们选择一个模型,点击后面的下载按钮下载下来(只需要下载一个,不同文件之间只有精度区分)。
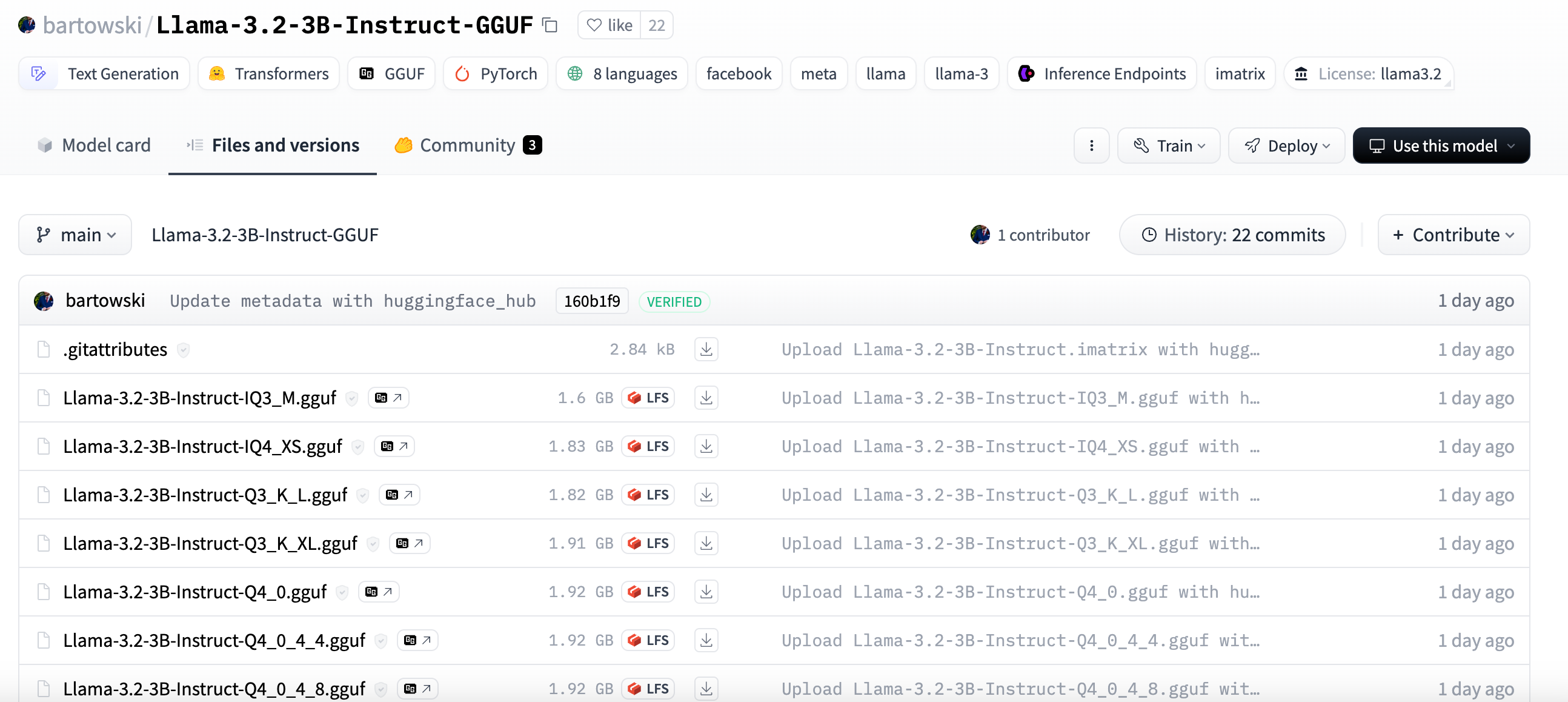
safetensors:
-–
更新于 2025-01-13:
更新 safetensors 模型的量化方式,因为 llama.cpp 项目进行了大更改,编译方式改为了 cmake
更新于 2025-01-22:
更新 windows 下的编译方式,从 WSL 虚拟环境编译变更为 本机编译
-–
和 gguf 相比,safetensors 要麻烦许多,我们需要借助 llama.cpp 项目,将 safetensors 转为 gguf 格式。
项目地址:llama.cpp
创建一个 python 项目,创建好虚拟环境(这里我 Python 的版本为 3.12.4,最好保持一致)

进入项目,拉取 llama.cpp 项目,因为我们需要借助 cmake 编译项目,所以需要提前安装,mac 可以通过 brew 命令安装:brew install cmake
windows 安装:
因为 windows 上的 cmake 还需要配合 c++ 和 c 编译器,所以比较麻烦,这里我分为 2 个部分,第一个是安装 cmake ,第二个是安装 w64devkit 并配置环境变量
cmake 的安装很简单,直接去官网下载安装就可以,注意安装的时候把添加到环境变量的框打上,这样就不用手动配置 cmake 的环境变量了。
w64devkit 则是一个整合了很多编译器的项目,其中就包含 c++ 和 c,并且是一个开源项目:w64devkit,这里我提供的是目前最新的 2.0 版本,下载后是一个 exe 文件,点开选择解压路径(注意最好不要包含中文),例如我解压到了 c 盘根目录,就是 C:\w64devkit ,下面我们配置环境变量,在系统的 PATH 中新增一条:C:\w64devkit\bin\bin,注意路径需要跟你解压的路径一致
下面就可以开始拉取 llama.cpp 项目并编译
1 | 拉取 llama.cpp 项目到本地 |
到这里,llama.cpp 工具的初始化就完成了。我们继续下载对应的大语言模型文件。这里我们需要用到 Hugging face 的官方工具 huggingface-cli。因为后面需要登陆,我们需要先注册一个 Huggingface 账号,并在个人设置内生成一个 token
现在我们可以继续输入下面 2 个命令,下载 huggingface_hub 工具并登陆
1 | 下载huggingface_hub工具 |
登陆成功后,我们就可以成功下载模型了,具体的下载的命令如下,这里对参数进行解释:download:后面跟要下载的模型,注意需要包含模型前缀,例如示例中的 Qwen/,一般直接在网页复制模型名就行。resume-download:如果下载中断,下次可以继续下载。local-dir:指定具体的下载路径
1 | huggingface-cli download --resume-download Qwen/Qwen2.5-Coder-7B-Instruct --local-dir /Users/sora33/download |
PS: 这里因为更新的原因,所以该部分后面大家看到的演示目录和自己的不一样是正常的,更新后只会让大家把 llama.cpp 项目拉下来
模型下载完成后,我们将下载的东西移动到 llama.cpp 项目下的 model 文件夹下,方便我们后续操作(如果没有 model 文件夹,创建一个即可)。
开始对模型进行转换,通过 llama.cpp 根目录下的 convert_hf_to_gguf.py 文件,转换对象是 model 文件夹,指定输出文件类型为 f16(16 位浮点数):
1 | python ./convert_hf_to_gguf.py ./model --outtype f16 |
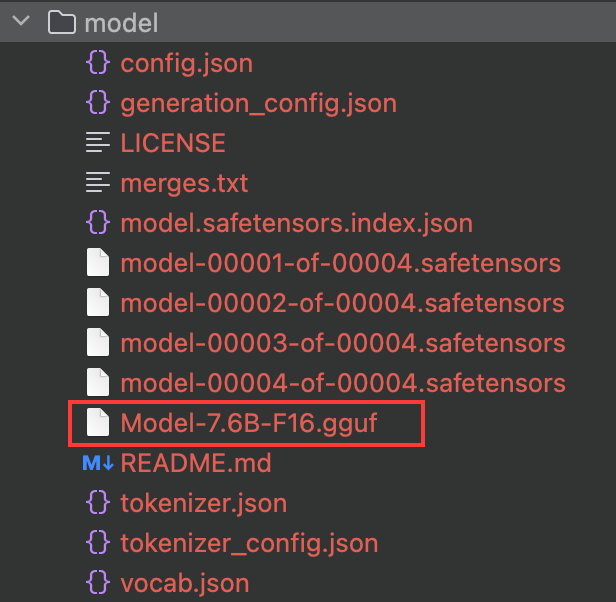
我们可以在 model 文件夹内看到结果文件,格式为 gguf,模型格式转换成功
PS:这里可能会遇到
ChatGLM4Tokenizer._pad() got an unexpected keyword argument 'padding_side'这个错误,原因是部分模型可能还不适配最新版本,所以我们需要把transformers降级,执行下面语句降级即可:
2
pip install transformers==4.34.0 若提示 tiktoken 未安装,直接使用
pip install tiktoken安装即可:
最后我们需要量化模型,先来简单介绍一下量化模型的作用。量化模型是通过降低浮点数来减少模型大小、加速推理和降低内存占用的过程,量化后模型精度会下降,但是效率和内存占用会贬低。量化等级按照从低到高排序(f16 精度最高,q2_K 最低):
q2_Kq3_Kq3_K_Sq3_K_Mq3_K_Lq4_0(受到推崇的)q4_1q4_Kq4_K_Sq4_K_Mq5_0q5_1q5_Kq5_K_Sq5_K_Mq6_Kq8_0f16
我们的量化命令如下,调用 llama.cpp bin 目录下的 llama-quantize,输入 Model-7.6B-F16.gguf、输出 qwen7.6B_q4_0.gguf,量化粒度为 q4_0。
1 | ./bin/llama-quantize ./model/Model-7.6B-F16.gguf qwen7.6B_q4_0.gguf q4_0 |
量化完成后,结果文件会输出到根目录下,这里我又移动到了 model 里面做对比。

同时可以看到,在 q4_0 粒度的量化下,直接少了 10 个 G,压缩效率非常好

编写启动脚本
现在我们拥有了 gguf 格式的文件,开始编写大模型的启动脚本 modelfile。新建一个 txt,FROM 后面跟我们模型的具体路径,PARAMETER 设置温度系数,值越高回答的随机性越大。SYSTEM 设置系统消息,用来定义角色或上下文,这里我们置空。完成后将文件保存并命名为 qwen.txt。(名字可以自定义)
1 | FROM /Users/sora33/PythonCode/qwen/ollama/model/qwen7.6B_q4_0.gguf |
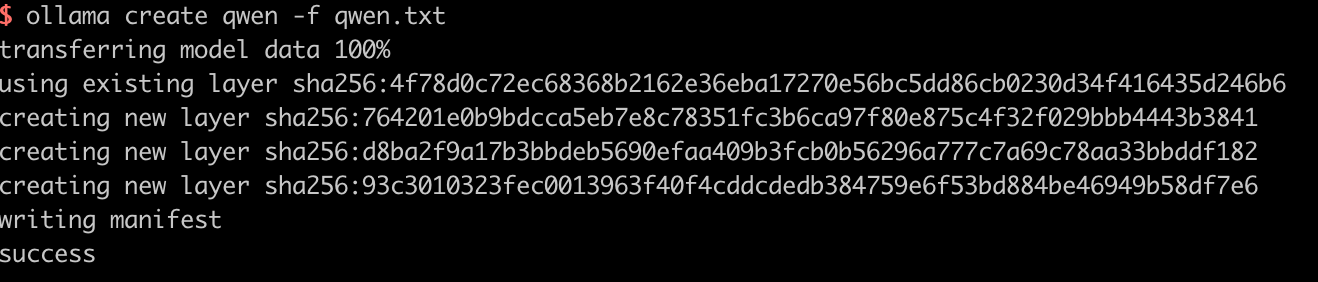
随后我们通过 ollama create 命令创建模型,模型命名 qwen,读取配置文件 qwen.txt。
1 | ollama create qwen -f qwen.txt |
命令执行后,等待片刻,模型会创建完毕,如下:
通过 run 命令启动模型并对话测试。

open-webui 可视化界面
目前为止,大模型已经创建完成并可以使用,但没有可视化页面只能在命令行内调用多少有点简陋。GitHub 上的一个开源项目 open-webui 可以完美适配 ollama,web 页面接入 ollama 也很简单,下面来具体操作一下,因为版本兼容问题,这里我们只以 Docker 为例,当然也可以通过 Python 启动(Python 版本必须需要在 3.11,这里我因为是 3.12 所以不方便演示)
Python:
1 | Python |
Docker:
我们不需要改动任何东西,只需要知道将原本的 8080 端口改到了 3000,如果 3000 跟你本地有冲突,也可以换成别的。执行这个 Docker 命令完成 open-webui 的创建。
1 | docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main |
访问 localhost:3000,进入主页面,会提示你登陆,这里简单注册一下就可以,数据都在你本地。之后左上角选定模型,就可以在 web 页面使用自己已经创建的大模型了
结束语
以上就是如何使用 ollama 配合 Huggingface 平台加载和运行大语言模型,特别是对于 safetensors 格式的模型。如果在流程上遇到什么问题,欢迎各位进行留言。
 微信
微信- 支付宝






