
自己对 Redis 的理解
数据类型
最基本的五种数据类型
String (字符串):最基本的数据类型
list(列表):相当于 java 语言里面的 LinkedList, 是链表结构,所以插入和删除非常快,时间复杂度是 O (1)
set(集合):相当于 hashset
hash (哈希):相当于 hashmap,数组 + 链表
zset(有序集合):在 set 的基础上 给每一个 value 会与了一个 score 代表这个 value 的排序权重
特殊的数据类型
HyperLogLogs(基数统计):只统计数量,不会存入值,占用空间极少。结果会有误差,约为 0.81。因此适用于网站在线人数,UV、注册 IP 数等对精准度要求不高的场景
geo(地理位置):可以将一个或多个和经纬度加入到 key 中
1 | geoadd china:city 116.40 39.90 beijing |
BitMap( 位存储): 只能存储 0 和 1 可以用来统计用户的活跃状态
1 | setbit sign userId 1 |
redis 为什么这么快
- 基于内存的操作
- 使用了非阻塞 IO 多路复用模型
- 单线程可以避免不必要的上下文切换和竞争条件,减少了这方面的性能消耗
redis 是否是多线程
redis 在 6.0 版本引入了多线程,在此之前 redis 为单线程。但多线程也只处理异步操作、持久化、集群通信等。网络 IO 以及键值存储仍然是由单线程去完成(因为 redis 的瓶颈不在 cpu 而在于 IO)
Redis 的线程模型
redis 内部实际上就是一个文件时间处理器。文件事件处理器结构包含 4 个部分:
多个 socket
IO 多路复用程序
文件事件分配器
事件处理器 (连接应答处理器,命令请求处理器 命令回复处理器)
多个 socket 可能会产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,将 socket 产生的事件放入队列中排队。事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。
redis 的持久化
redis 具有 RDB 和 AOF 以及混合持久化 (redis4.0 引入) 三种持久化方式。
RDB 是 redis 默认的持久化方式,类似于快照,在某个时间点,将 redis 在内存中的数据库,也就是键值对等信息保存到磁盘里面,生成的 RDB 文件是经过压缩的二进制文件。可以通过 SAVE 或 BGSAVE 进行生成快照。SAVE 是同步的,BGSAVE 是异步的,会生成一个子进程去处理。
优点:因为是压缩过的二进制文件,所以占用空间很小,适合灾难恢复。可以最大化 redis 的性能,只需要一个子进程来处理保存的工作,在恢复数据是比 AOF 速度要快
缺点: RDB 是隔一段时间进行持久化,如果持久化的时候发生故障宕机,意味着丢失数据
AOF 则保存 redis 服务器执行的所有写操作命令来记录数据库状态,服务器重启时,重新执行这些命令来还原数据集,可以通过 appendonly on 来开启。
优点是比 RDB 可靠,可以通过设置 fsync 策略,no,everysec 和 always 默认为 everysec 。假如说发生了宕机,最多丢失 1 秒钟的数据,如果写入时磁盘已满或者宕机,可以通过 redis-check-aof 工具来修复
缺点:对于相同的数据集,AOF 文件一般比 RDB 文件大,且恢复速度慢
混合持久化是在 4.0 开始有的,5.0 默认开启。可以通过 config aof-use-rdb-preamble 命令查看是否开启。config set aof-use-rdb-preamble yes 用来开启混合持久化。不过这样设置的话,redis 重启我们设置的混合持久化就会失效,永久生效可以通过修改 redis 配置文件开启 配置文件中的 aof-use-rdb-preamble yes 来开启。文件格式如下
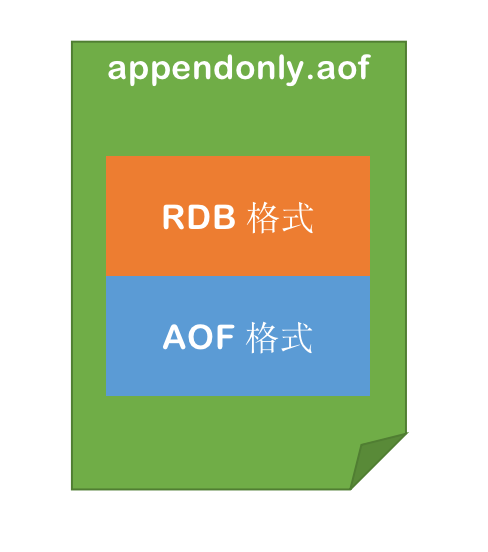
优点很明显,混合持久化结合了 RDB 和 AOF 持久化的优点,开头为 RDB 的格式,使得 Redis 可以更快的启动,同时结合 AOF 的优点,又减低了大量数据丢失的风险。但缺点是添加了 RDB 格式的内容,使得 AOF 文件的可读性变得很差。兼容性也不高,如果开启混合持久化,那么此混合持久化 AOF 文件,就不能用在 Redis 4.0 之前版本了。
Redis 的过期策略
惰性删除只会在每次获取键的时候检查键是否过期。如果过期就删除
定期删除:每隔 100ms 一定的时间,就对数据库进行一次随机检查,删除里面的过期键、对 cpu 和内存比较平衡的模式
定时删除:会给每一个 key 设置一个定时器,时间到了就删除
redis 的淘汰策略
当 redis 的内存空间已满时,会根据配置的过期策略进行对应操作
No eviction: 默认策略,不移除任何 key,直接返回错误
Allkeys-lru: 在所有的 key 中,移除最近最少使用的 key
Allkeys-random: 在所有的 key 中,随机移除 key
Volatile-lru: 在设置过期时间的 key 中,移除最近最少使用的 key
Volatile-random: 在设置过期时间的 key 中,随机移除 key
Volatile-ttl: 在设置过期时间的 key 中,挑选 ttl (剩余时间) 短的移除
4.0 之前有 6 种过期策略,4.0 之后新加入 2 个过期策略
Volatile-lfu: 在设置过期时间的 key 中,使用 LFU 算法淘汰部分 key 4.0 新增
Allkeys-lfu: 在所有 key 中,使用 LFU 算法淘汰部分 key 4.0 新增
Redis 哨兵模式的特点
集群监控 监控着 redis 的 master 和 slave 的工作是否正常
消息通知:当发现 redis 实例有故障,会通知管理员
故障转移:如果 master 节点宕机了 会将从 slave 中选举一个新的 master 并进行数据同步
哨兵集群至少需要三个节点,而且是奇数,保证自己的健壮性。哨兵选举涉及到判断主节点宕机的机制。有主管宕机和客观宕机。主观宕机,就是一个哨兵觉得自己 master 宕机了,这个叫主观宕机。客观宕机是我们设置的 quorum (同意数),至少有多少个哨兵认为 master 宕机了,master 才是真正的宕机了。
双写的考虑
先更新数据库在更新缓存: 现在有 A 和 B 两个请求,都是修改数据的。但是因为网络原因,B 的请求比 A 先完成了。那么这个时候,A 在更新。最后缓存存入的是 A 修改后的数据,直接导致了数据不一致性。
先删缓存再更新数据库: 还是 2 个请求。A 和 B A 是更新数据的,B 是查询数据的。现在我们 A 请求开始执行了。发现有缓存,把缓存删掉了,在进行写操作,但没有写入完成的时候。B 来查询了,发现没有缓存。去数据库查询,并且将该数据存到缓存。这个时候我们的 A 更新完之后。缓存内的数据仍然是脏数据。
扯淡的解决方案!!!!!!!!!!
于是我们就衍生出一种延时双删。将 A 更新完之后,延时 1S 左右。具体要根据我们的业务逻辑判断。如果 mysql 有主从复制还得更长。再休眠一小段时间后,再对这条数据的缓存进行一个删除。就是为了删掉这个脏数据。
先更新数据库,再删除缓存: 现在请求 A 和请求 B。请求 A 来进行查询,请求 B 来进行更新数据库。而且两者操作的都是同一条数据。A 是查询,B 是写入。对于 mysql 来说。查询的性能是比写入要高很多的。所以绝大多数情况,都是查询请求先完成。然后请求 B 是要晚于请求 A 的。B 写入完成后。删除掉 redis 中的旧缓存。
缓存穿透、缓存雪崩、缓存击穿
缓存穿透: 访问一个缓存和数据库都不存在的 key,此时会直接访问数据库,并且因为查不到数据,无法写入缓存,所以下一次还会访问数据库。流量大的情况可能会导致数据库宕机
解决方案:
缓存空值:可以将空值写入缓存,设置一个较短的过期时间
布隆过滤器:使用布隆过滤器来存储所有可能被访问的 key,不存在的 key 直接被过滤,存在的 key 则去查询缓存和数据库
缓存击穿: 如果有一个热点 key,在缓存过期的一瞬间,有大量的请求打过来,因为此时缓存过期了,所以所有的请求都会走数据库,造成顺时数据库请求量大,可能导致数据库宕机
解决方案:
使用互斥锁:只有第一个线程可以拿到锁并执行数据库查询,其他的线程就在锁外面阻塞。
等第一个线程把数据写入缓存后,剩下的线程就可以直接从缓存取值
永不过期:可以直接将这个热点数据设置为永不过期,通过定时异步的方式去更新数据
缓存雪崩: 设置缓存时使用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到数据库,数据库因为请求量大,压力骤增,导致数据库挂掉、和击穿很像,击穿是一个 key,雪崩是多个 key
解决方案:
使用互斥锁:
永不过期:
将过期的时间打散:可以在原来的时间上加随机值,防止每个缓存的过期时间一样
其他数据类型
 微信
微信- 支付宝







